Swin Transformer V2 Encoder for midi-rae — drop-in replacement for ViTEncoder
Design Overview
Motivation: Multi-Scale Understanding
We’re not doing mere image segmentation. The representations at different scales may be very different from one another and mapped non-linearly. Consider: the top-level representation could be something about musical genre. The next level down could be something about what part of the song we’re in. The next level down could be which part of the verse or chorus we’re in. The next level could be a given musical phrase. The next level could be the individual notes in the phrase.
Same Info, Organized Differently
ViT: The default ViT we’ve been using has 65 patches with 256 dimensions each: 65 * 256 = 16,640 encoding parameters.
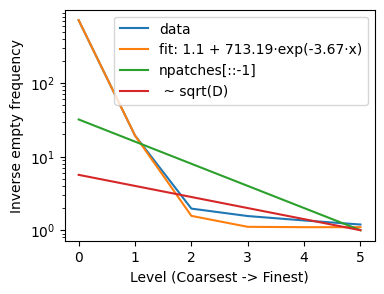
For the a Swin with 6 stages, embed_dim=8, patch_h=patch_w=4, so the finest grid is 32×32:
Level
Patch Size (px)
Grid
Dim
Scalars
0 (coarsest)
128x128
1×1
256
256
1
64x64
2×2
128
512
2
32x32
4×4
64
1,024
3
16x16
8×8
32
2,048
4
8x8
16×16
16
4,096
5 (finest)
4x4
32x32
8
8,192
Total
16,128 encoding parameters
…So the Swin has basically the same amount of information as the ViT (actually slightly less!), it’s just organized differently.
What this module does
SwinEncoder is a drop-in replacement for ViTEncoder that uses the Swin Transformer V2 architecture. It takes a piano roll image (B, 1, 128, 128) and returns an EncoderOutput with hierarchical multi-scale patch states.
Why Swin V2?
Hierarchical representation: 7 levels from finest (64×64 grid, dim=4) down to a single CLS-like token (1×1, dim=256), compared to ViT’s flat single-scale output
Efficient attention: Windowed attention with shifted windows — O(N) instead of O(N²)
V2 improvements: Cosine attention with learned log-scale temperature, continuous position bias via CPB MLP, res-post-norm for training stability
Architecture
Stage
Grid
Patch covers
Dim
Depths
Heads
0
64×64
2×2
4
1
1
1
32×32
4×4
8
1
1
2
16×16
8×8
16
2
1
3
8×8
16×16
32
2
2
4
4×4
32×32
64
6
4
5
2×2
64×64
128
2
8
6
1×1
128×128
256
1
16
Config is in configs/config_swin.yaml.
Implementation approach
We use timm’s SwinTransformerV2Stage directly — no copied or modified Swin internals. Our SwinEncoder wrapper handles only:
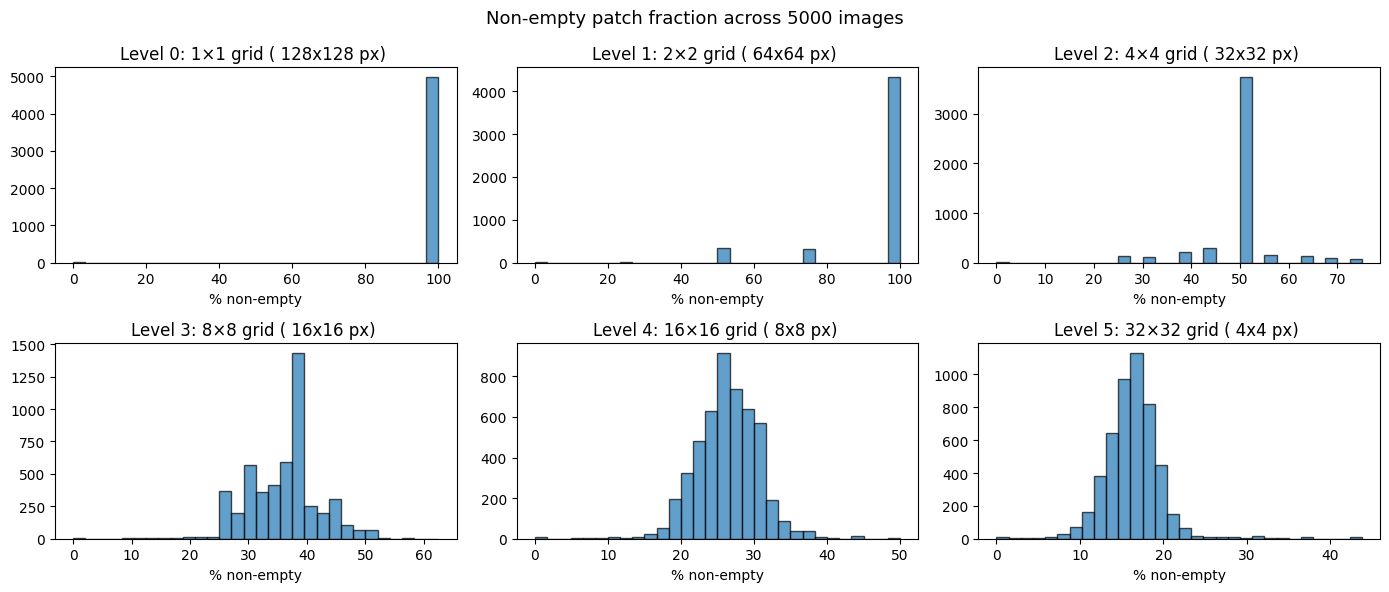
Empty patch detection — patches where all pixels are black get a learnable empty_token
MAE masking (SimMIM-style) — masked patches get a learnable mask_token, grid stays intact so windowed attention works unmodified. Two-rate sampling: non-empty patches masked at mask_ratio, empty patches at mask_ratio × empty_mask_ratio (default 5%)
Hierarchical output — collects each stage’s output into HierarchicalPatchState (coarsest-first), packaged as EncoderOutput
Key differences from ViTEncoder
No CLS token (stage 6’s single 1×1 token serves as a global summary)
No RoPE (Swin V2 uses its own continuous position bias)
MAE masking keeps all tokens (SimMIM-style) — no compute savings but preserves spatial grid
empty_mask_ratio controls how often trivial-to-reconstruct empty patches are masked
TODOs
HierarchicalPatchState could store window_size per level
EncoderOutput could store scale metadata (downsample factors per level)
Inter-stage patch masking: dropout-style masking between encoder stages, tapered ratio per stage (mae_ratio / 2**stage_idx), using a learnable mask token. Forces robust representations at every scale.
Self-distillation (DINO/iBOT-style): EMA teacher provides latent targets at all scales, eliminating need for pixel-level reconstruction at coarser levels.
Multi-scale reconstruction losses: reconstruct downsampled piano rolls at each hierarchy level (requires bidirectional decoder, e.g. U-Net with skip connections).
SwinEncoder
def SwinEncoder( img_height:int, # Input image height in pixels (e.g. 128) img_width:int, # Input image width in pixels (e.g. 128) patch_h:int=4, # Patch height for initial embedding patch_w:int=4, # Patch width for initial embedding in_chans:int=1, # Number of input channels (1 for piano roll) embed_dim:int=8, # Base embedding dimension (doubles each stage) depths:tuple=(1, 2, 2, 6, 2, 1), # Number of transformer blocks per stage num_heads:tuple=(1, 1, 2, 4, 8, 16), # Attention heads per stage window_size:int=8, # Window size for windowed attention mlp_ratio:float=4.0, # MLP hidden dim = embed_dim * mlp_ratio qkv_bias:bool=True, # Add bias to QKV projections drop_rate:float=0.0, # Dropout after patch embedding proj_drop_rate:float=0.0, # Dropout after attention projection attn_drop_rate:float=0.0, # Dropout on attention weights drop_path_rate:float=0.1, # Stochastic depth rate norm_layer:type=LayerNorm, # Normalization layer class mae_ratio:float=0.0, # Fraction of non-empty patches to mask (0=no masking) empty_mask_ratio:float=0.05, # Mask rate for empty patches relative to mae_ratio squash_coarse:bool=False, # Overwrite course level empty patch tokens with a learned empty patch token.):
Swin Transformer V2 Encoder for midi-rae — drop-in replacement for ViTEncoder. (Wrapper for timm routines)
FPN-style MAE decoder for SwinEncoder hierarchical output. Top-down pathway fuses all levels, reconstructs at finest scale.
SwinDecoder
def SwinDecoder( img_height:int=128, # Output image height img_width:int=128, # Output image width patch_h:int=4, # Patch height (must match encoder) patch_w:int=4, # Patch width (must match encoder) out_channels:int=1, # Output channels (1 for piano roll) embed_dim:int=8, # Base embedding dim (same as encoder) depths:tuple=(1, 2, 2, 6, 2, 1), # Encoder depths (finest→coarsest); reversed internally num_heads:tuple=(1, 1, 2, 4, 8, 16), # Encoder heads (finest→coarsest); reversed internally window_size:int=8, # Window size for windowed attention mlp_ratio:float=4.0, # MLP hidden dim = dim * mlp_ratio qkv_bias:bool=True, # Bias in QKV projections drop_path_rate:float=0.1, # Stochastic depth rate proj_drop_rate:float=0.0, # Dropout after attention projection attn_drop_rate:float=0.0, # Dropout on attention weights norm_layer:type=LayerNorm):
Swin V2 Decoder for midi-rae — symmetric multi-stage decoder.
Mirrors the encoder architecture: processes coarsest→finest with Swin V2 windowed attention at every spatial scale, fusing encoder skip connections via lateral projections at each level.
Pass the same config values (embed_dim, depths, num_heads) as the encoder; they are reversed internally for the coarsest→finest decode direction.
Takes EncoderOutput directly (same interface as SwinMAEDecoder).
TODO: Try ConvTranspose2d or PixelShuffle as alternatives to linear unpatchify. TODO: Make the unpatchify head swappable via a factory or argument.
Summarizes each hierarchy level into bottleneck tokens via cross-attention, mixes across levels with self-attention, then predicts target embeddings at all positions via reverse cross-attention. Loss should be computed externally on masked positions only, e.g.: preds, masks = predictor(enc_out_context) targets = enc_out_target.patches.levels loss = sum(((p[~m] - t.emb[~m])**2).mean() for p, m, t in zip(preds, masks, targets))
Flow: Mask → Summarize → Mix → Predict
Test that:
from midi_rae.utils import param_countfrom midi_rae.losses import safe_meanmep = SwinMaskedEmbeddingPredictor()print(f"mep model parameters: {param_count(mep)[1]:,}")enc_out1 = enc_out # for main code, it'll be enc_out1 that will be the target z1 = [lvl.emb for lvl in enc_out1.patches.levels]x2 = torch.randn(B, C, H, W)enc_out2 = enc(x2) # for main code, it'll be enc_out2 that will get trained onemb_pred, masks = mep(enc_out2) # predict from masked-input enc_out2, what the comparable embeddings are in enc_out1print(f"len(emb_pred) = {len(emb_pred)}; (B, N, D)")with torch.no_grad(): # just for testing/demo, no grads mep_loss =0for lev, (emb, mask) inenumerate(zip(emb_pred, masks)): print(f"Level {lev}: emb.shape = {tuple(emb.shape)}, mask.shape = {mask.shape}, avg # visible = {mask.sum()/B:.1f}, avg # masked = {(~mask).sum()/B:.1f}") target = enc_out1.patches[lev].emb mep_loss = mep_loss + safe_mean((emb[~mask] - target[~mask])**2) # mask=0 means masked , mean across each level mep_loss = mep_loss / enc_out.patches.num_levels # average over levelsprint("mep_loss = ",mep_loss)