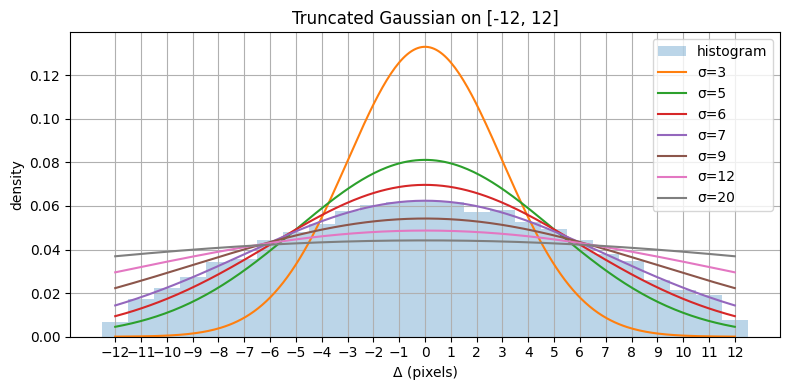
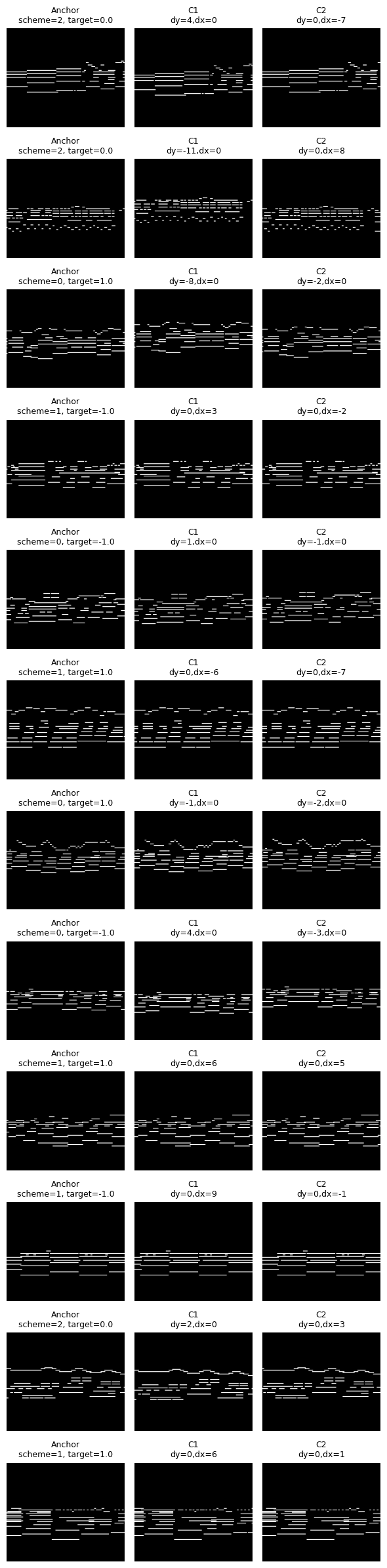
Loading 818 train files from ~/datasets/POP909_images_basic... Finished loading.
len(data) = 81800
data.actual_len = 818
data_dict =n {'img1': tensor([[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]]), 'img2': tensor([[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]]), 'deltas': tensor([3., 6.]), 'file_idx': 499}
data_dict['img1'].sum() = tensor(402.)
data_dict['img2'].sum() = tensor(408.)