# #| export
# def SIGReg_nochunk(x, global_step, num_slices=256):
# """SIGReg with Epps-Pulley statistic. x is (N, K) tensor."""
# with torch.amp.autocast('cuda', enabled=False):
# x = x.float()
# device = x.device
# g = torch.Generator(device=device).manual_seed(global_step)
# proj_shape = (x.size(1), num_slices)
# A = torch.randn(proj_shape, generator=g, device=device)
# A = A / (A.norm(dim=0, keepdim=True) + 1e-10) # normalize columns
# # Epps-Pulley statistic
# t = torch.linspace(-5, 5, 17, device=device) # values used in LeJEPA paper, worked for SSLtoy
# exp_f = torch.exp(-0.5 * t**2) # theoretical CF for N(0,1)
# x_t = (x @ A).unsqueeze(2) * t # (N, M, T)
# ecf = (torch.exp(1j * x_t).mean(dim=0)).abs() # empirical CF
# diff = (ecf - exp_f).abs().square().mul(exp_f) # weighted L2 distance
# #N = x.size(0) # With respect to Yann: Don't scale by N because then if you change the batch size you have to retune lambd by hand ugh
# T = torch.trapz(diff, t, dim=1).sum() #* N # sum here is over num slices, not data points
# return Tlosses
LeJEPA, GAN discriminator, …aand more
Safe Mean
Turns out zero element tensors will yield NaN when you try to run .mean(), so…
safe_mean
def safe_mean(
t, dim:NoneType=None
):
safe replacement for torch.mean( ). can’t be used as a suffix though
LeJEPA Loss
For an interactive overview of LeJEPA, see https://www.scotthawley.com/ssltoy/
SIGReg loss
chunked for speed on small GPUs
SIGReg
def SIGReg(
x, global_step, num_slices:int=256, chunk_size:int=32
):
SIGReg with Epps-Pulley statistic. x is (N, K) tensor. Chunked to reduce memory pressure -> More GPU utilization. :-)
# Test SIGReg with random embeddings
batch_size, embed_dim = 32, 64
x = torch.randn(batch_size, embed_dim)
loss = SIGReg(x, global_step=0, num_slices=256)
print(f"SIGReg loss: {loss.item():.4f}")SIGReg loss: 2.8732Attraction loss
Drawing similar pairs together in latent space
attraction_loss
def attraction_loss(
z1, z2, # embeddings of two "views" of the same thing (in batches)
deltas:NoneType=None, # optional/TBD: info on semantic 'distance' between z1 & z2
alpha:float=1.0, # scaled margin strenth
kwargs:VAR_KEYWORD
):
Pull similar ‘views’ together, but with delta-scaled margin to prevent over-collapse
Factorization (Triplet) Loss
To encourage “soft” factorization/decomposition in pitch vs time. See post https://drscotthawley.github.io/blog/posts/FactorizingSoftly.html
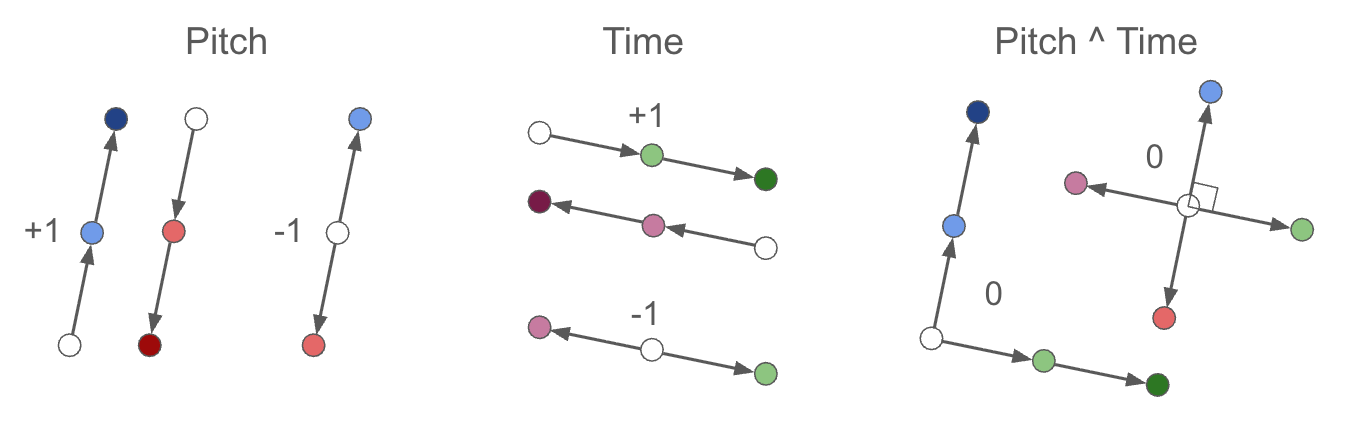 where
where targets are +1 for parallel, (same-type, same-sign), −1 for antiparallel (same-type, opposite-sign), or 0 for orthogonal (cross-type):
factorization_loss
def factorization_loss(
z_anchor, z_crop1, z_crop2, targets
):
Test that:
B, N, D = 10, 32, 16
z1 = torch.randn((B,N,D))
z2 = torch.randn((B,N,D))
z3 = torch.randn((B,N,D))
targets = torch.randint(-1, 2, (B,)).unsqueeze(-1)
f = factorization_loss( z1, z2, z3, targets)
print("f.mean = ",f.mean().item())f.mean = 0.8786262273788452LeJEPA
def LeJEPA(
z1, z2, global_step, z3:NoneType=None, valids:NoneType=None, target:NoneType=None, lambd:float=0.5,
deltas:NoneType=None, psize:NoneType=None, sigreg_on_both:bool=True, sigreg_prefac:float=0.5,
lambda_fact:float=0.5
):
Main LeJEPA loss function
# Test LeJEPA loss
batch_size, embed_dim = 32, 64
z1 = torch.randn(batch_size, embed_dim, requires_grad=True)
z2 = torch.randn(batch_size, embed_dim, requires_grad=True)
loss = LeJEPA(z1, z2, global_step=0, lambd=0.5)
print(f"LeJEPA loss: {loss['loss'].item():.4f}")
print(f" Attraction: {attraction_loss(z1, z2).item():.4f}")
print(f" SIGReg: {SIGReg(torch.cat((z1, z2), dim=0), global_step=0).item():.4f}")
z3 = torch.randn(batch_size, embed_dim, requires_grad=True)
target = torch.randint(-1, 2, (batch_size,)).unsqueeze(-1)
loss = LeJEPA(z1, z2, global_step=0, z3=z3, target=target, lambd=0.5, lambda_fact=0.5)
print(f"LeJEPA loss: {loss['loss'].item():.4f}")
print(f" Attraction: {loss['sim']:.4f}")
print(f" SIGReg: {loss['sigreg']:.4f}")
print(f" Factorization : {loss['fact']:.4f}")
print("loss['loss'].requires_grad =", loss['loss'].requires_grad)LeJEPA loss: 1.8157
Attraction: 2.0864
SIGReg: 1.5487
LeJEPA loss: 2.0427
Attraction: 2.0864
SIGReg: 1.5450
Factorization : 0.9080
loss['loss'].requires_grad = TrueFull Encoder Loss
anchor_loss
def anchor_loss(
z1, z2
):
Anchor embeddings of empty patches to the origin
calc_enc_loss
def calc_enc_loss(
z1, z2, global_step, z3:NoneType=None, deltas:NoneType=None, target:NoneType=None, lambd:float=0.5,
non_emptys:tuple=(None, None), lambda_anchor:float=0.05, lambda_fact:float=0.5, psize:NoneType=None
):
Main loss function for Encoder
calc_enc_loss_multiscale
def calc_enc_loss_multiscale(
z1, z2, global_step, img_size, z3:NoneType=None, deltas:NoneType=None, target:NoneType=None, lambd:float=0.5,
non_emptys:NoneType=None, lambda_anchor:float=0.05, lambda_fact:float=0.5, lambda_mep:float=0.0,
mep_model:NoneType=None, debug:bool=False
):
Compute encoder loss at each hierarchy level of the Swin encoder. really really this time
Masked (Auto)Encoder Loss
calc_mae_loss
def calc_mae_loss(
recon_patches, img, enc_out, lambda_visible:float=0.1,
pos_weight:float=2.0, # for class imbalance; white pixels worth more than black; value tuned experimentally
):
BCE loss on reconstructed patches, with optional downweighting of visible patches
Decoder Loss
calc_dec_loss
def calc_dec_loss(
decoder, enc_out, img_real,
pos_weight:float=1.0, # weighting positive (white pixels) to negative (black); value tuned experimentally
note_weights:NoneType=None,
lambda_mse:float=0.2, # tiny bit of MSE to blur and let nearby pixels 'talk to each other' and resolve off-by-one errors
):
decoder loss function)
Adversarial Loss
Not using this at all. Started out with this since many computer vision models do this, but our binary piano roll images are very different from photos & audio. BCE is sufficient.
# #| export
# class PatchGANDiscriminator(nn.Module):
# def __init__(self, in_ch=1, base_ch=64, n_layers=3, use_spectral_norm=True):
# super().__init__()
# norm = nn.utils.spectral_norm if use_spectral_norm else (lambda x: x)
# layers = [norm(nn.Conv2d(in_ch, base_ch, kernel_size=4, stride=2, padding=1)), nn.LeakyReLU(0.2, True)]
# ch = base_ch
# for i in range(1, n_layers):
# ch_next = min(ch * 2, 512) # double channels each layer, but cap at 512 to limit params
# layers += [norm(nn.Conv2d(ch, ch_next, kernel_size=4, stride=2, padding=1)), nn.LeakyReLU(0.2, True)]
# ch = ch_next
# layers.append(norm(nn.Conv2d(ch, 1, kernel_size=4, stride=1, padding=1)))
# self.net = nn.Sequential(*layers)
# def forward(self, x): return self.net(x)