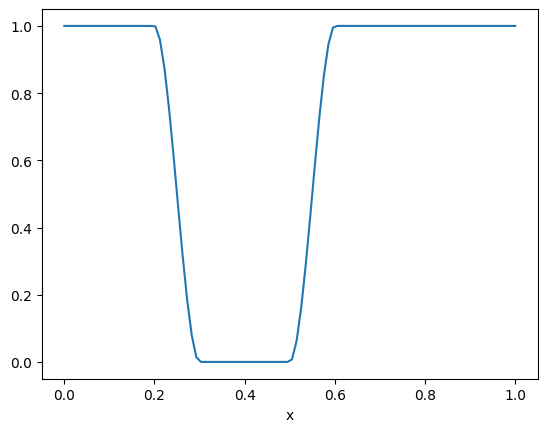
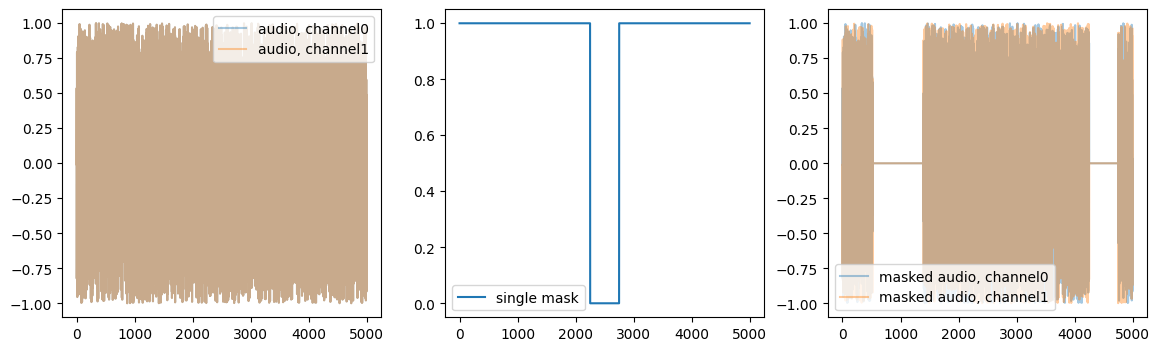
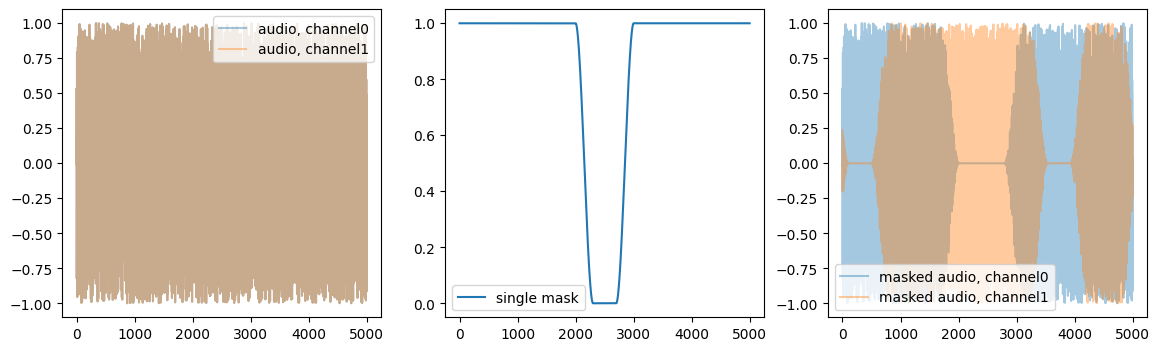
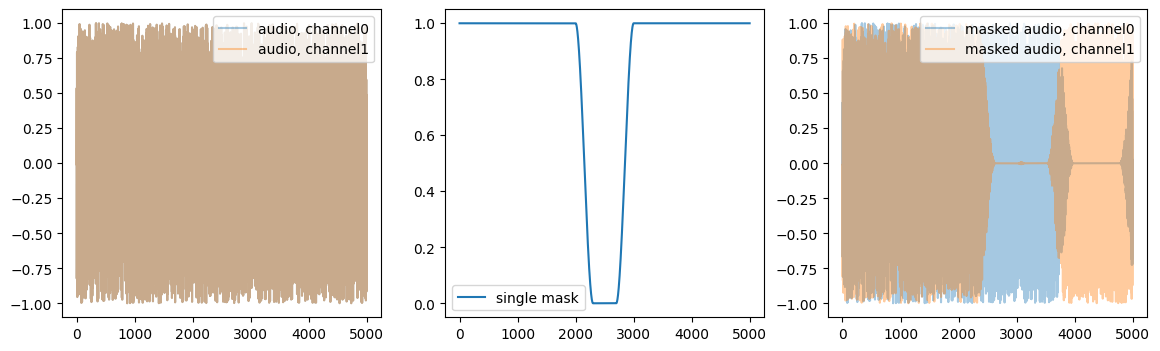
batch = [tensor([[[[ 0.4060, 0.3965, 0.3820, ..., 0.5274, 0.5349, 0.5406],
[ 0.5739, 0.5558, 0.5435, ..., 0.5655, 0.5707, 0.5763]],
[[-0.3591, -0.3761, -0.3705, ..., -0.2486, -0.3406, -0.4426],
[-0.2027, -0.1295, -0.0775, ..., -0.3002, -0.3320, -0.3603]],
[[-0.1131, -0.0873, -0.1157, ..., 0.0386, 0.0382, 0.0378],
[-0.2008, -0.1766, -0.1978, ..., 0.0127, 0.0131, 0.0133]],
[[ 0.1581, 0.0486, -0.0798, ..., -0.0239, -0.1204, -0.1762],
[ 0.0942, 0.0589, 0.0190, ..., -0.1309, -0.1081, -0.0622]]]]), [{'text': ['playing song in album The Cult From Moon Mountain, titled Circle Moon, by Fursaxa, of which the genre is Folk, the language code is en, the composer is Tara Burke, the date created is 2008-11-26 02:13:59'], 'original_data': {'title': ['FMA: A Dataset For Music Analysis'], 'description': ['Free Music Archive (FMA), an open and easily accessible dataset suitable for evaluating several tasks in MIR, a field concerned with browsing, searching, and organizing large music collections.'], 'license': ['MIT License'], 'filename': ['000714.mp3'], 'genre': ['Folk'], 'album': ['The Cult From Moon Mountain'], 'song_title': ['Circle Moon'], 'artist': ['Fursaxa'], 'duration': tensor([338]), 'composer': ['Tara Burke'], 'date_recorded': ['2008-11-26 02:13:59'], 'language_code': ['en']}, 'seconds_start': tensor([69]), 'seconds_total': tensor([339]), 'prompt': ['playing song in album The Cult From Moon Mountain, titled Circle Moon, by Fursaxa, of which the genre is Folk, the language code is en, the composer is Tara Burke, the date created is 2008-11-26 02:13:59']}, {'text': ["playing song titled I'm Quitting, in album Hank IV Live at WFMU on Brian's Show on 11/18/2008, by Hank IV, of which the language code is en, the date created is 2008-12-04 20:08:12, the genre is Rock"], 'original_data': {'title': ['FMA: A Dataset For Music Analysis'], 'description': ['Free Music Archive (FMA), an open and easily accessible dataset suitable for evaluating several tasks in MIR, a field concerned with browsing, searching, and organizing large music collections.'], 'license': ['MIT License'], 'filename': ['003688.mp3'], 'genre': ['Rock'], 'album': ["Hank IV Live at WFMU on Brian's Show on 11/18/2008"], 'song_title': ["I'm Quitting"], 'artist': ['Hank IV'], 'duration': tensor([146]), 'composer': ['nan'], 'date_recorded': ['2008-12-04 20:08:12'], 'language_code': ['en']}, 'seconds_start': tensor([38]), 'seconds_total': tensor([147]), 'prompt': ["playing song titled I'm Quitting, in album Hank IV Live at WFMU on Brian's Show on 11/18/2008, by Hank IV, of which the language code is en, the date created is 2008-12-04 20:08:12, the genre is Rock"]}, {'text': ['playing song titled Rother, Dinger You and Me, by Antiguo Automata Mexicano, of which the date created is 2008-12-04 19:37:15, the language code is en, the genre is Electronic'], 'original_data': {'title': ['FMA: A Dataset For Music Analysis'], 'description': ['Free Music Archive (FMA), an open and easily accessible dataset suitable for evaluating several tasks in MIR, a field concerned with browsing, searching, and organizing large music collections.'], 'license': ['MIT License'], 'filename': ['003345.mp3'], 'genre': ['Electronic'], 'album': ['nan'], 'song_title': ['Rother, Dinger You and Me'], 'artist': ['Antiguo Automata Mexicano'], 'duration': tensor([312]), 'composer': ['nan'], 'date_recorded': ['2008-12-04 19:37:15'], 'language_code': ['en']}, 'seconds_start': tensor([150]), 'seconds_total': tensor([313]), 'prompt': ['playing song titled Rother, Dinger You and Me, by Antiguo Automata Mexicano, of which the date created is 2008-12-04 19:37:15, the language code is en, the genre is Electronic']}, {'text': ['playing song titled Poctoth, in album Mono M::P Free, by Thomas Dimuzio, of which the language code is en, the genre is Electronic, the date created is 2008-11-26 03:21:17'], 'original_data': {'title': ['FMA: A Dataset For Music Analysis'], 'description': ['Free Music Archive (FMA), an open and easily accessible dataset suitable for evaluating several tasks in MIR, a field concerned with browsing, searching, and organizing large music collections.'], 'license': ['MIT License'], 'filename': ['002074.mp3'], 'genre': ['Electronic'], 'album': ['Mono M::P Free'], 'song_title': ['Poctoth'], 'artist': ['Thomas Dimuzio'], 'duration': tensor([126]), 'composer': ['nan'], 'date_recorded': ['2008-11-26 03:21:17'], 'language_code': ['en']}, 'seconds_start': tensor([101]), 'seconds_total': tensor([127]), 'prompt': ['playing song titled Poctoth, in album Mono M::P Free, by Thomas Dimuzio, of which the language code is en, the genre is Electronic, the date created is 2008-11-26 03:21:17']}], [[tensor([0.2057], dtype=torch.float64), tensor([0.2218], dtype=torch.float64)], [tensor([0.2613], dtype=torch.float64), tensor([0.2987], dtype=torch.float64)], [tensor([0.4829], dtype=torch.float64), tensor([0.5004], dtype=torch.float64)], [tensor([0.7989], dtype=torch.float64), tensor([0.8419], dtype=torch.float64)]]]
Success!