To be added: - Diffusion models: masked DVAE , archinet’s - Others groups’: JukeBox (as “IceBox”)
Wrapper API: “GivenModelClass”
We’re going to make a bunch of wrappers that are PyTorch modules. The API for the wrappers will be as follows: - .encode(): encodes the (batch of) (raw) audio waveform(s) into encodings aka “representations” reps, where reps should have shape ([b,]c,d,n) where b is an optional batch dimension (matching that of the waveform input), c may or may not correspond to actual audio channels (e.g. for DVAE, c=1 even for stereo). d and n are typically the “dimensions” of the embeddings and the time step/frame, respectively, but some models may not respect this. - .decode(): decodes the (batch of) encodings/representations from the encoder into “reconstruction” waveforms recons - .forward(): calls bothencode() and decode() in succesion, returns tuple (reps, recons) - .setup(): an optional routine that will load checkpoints & do other ‘init’ stuff (but not done automatically in init) - self.ckpt_info{}: dict that includes URL and approved hash value for pretrained model checkpoint. Default is no info
Resampling ../aeiou/examples/example.wav from 44100 Hz to 48000 Hz
waveform.shape = torch.Size([2, 55728])
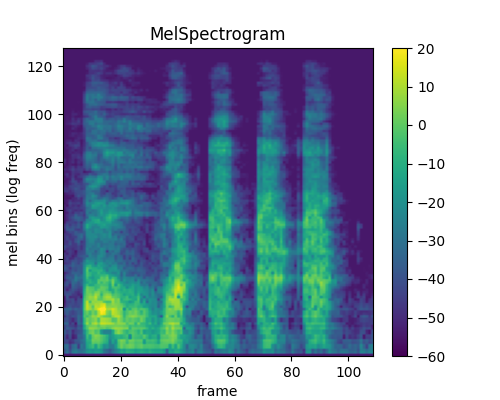
/Users/shawley/envs/aa/lib/python3.10/site-packages/torchaudio/functional/functional.py:571: UserWarning: At least one mel filterbank has all zero values. The value for `n_mels` (128) may be set too high. Or, the value for `n_freqs` (513) may be set too low.
warnings.warn(
<matplotlib.legend.Legend>
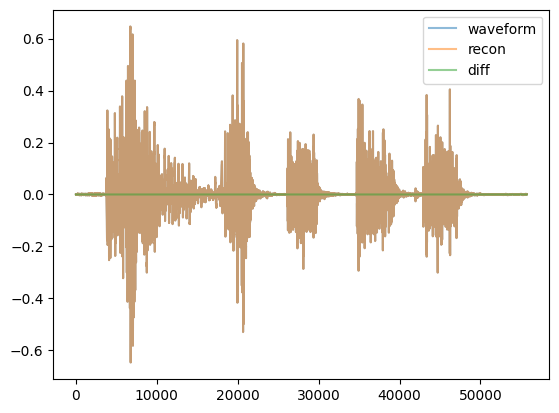
Now show that “recon” results of the inverse transform are very close to the original waveform:
device = get_device()print("device =",device)if torch.device('mps') == device: print("Actually MPS is going to cause 'TypeError: Trying to convert ComplexFloat to the MPS backend but it does not have support for that dtype', so you'll get cpu") device='cpu'given_model = SpectrogramAE().to(device)spec, recon = given_model.forward(waveform.to(device))print("spec.shape, recon.shape = ",spec.shape, recon.shape)print("spec.dtype = ",spec.dtype)diff = recon.cpu()-waveform#playable_spectrogram(diff, output_type='live') #plot/play the difference#spec_graph = audio_spectrogram_image(diff, justimage=False, db=False, db_range=[-60,20])#display(spec_graph)for c inrange(waveform.shape[0]): plt.plot(diff[c].cpu().numpy(), label=f'channel {c}')plt.legend()
device = mps
Actually MPS is going to cause 'TypeError: Trying to convert ComplexFloat to the MPS backend but it does not have support for that dtype', so you'll get cpu
spec.shape, recon.shape = torch.Size([2, 513, 257]) torch.Size([2, 55728])
spec.dtype = torch.complex64
# test thati_love_slow_code =False# This is super slow for reasons I don't know yetif i_love_slow_code: melspecfunc = MelSpectrogramAE().to(device) melspec, recon4 = melspecfunc.forward(waveform.to(device))print("melspec.device, melspec.shape, recon4.shape = ",melspec.device, melspec.shape, recon4.shape )print("melspec.dtype =",melspec.dtype) recon4 = recon4.to('cpu')#display(playable_spectrogram(recon4, output_type='live'))
if i_love_slow_code: diff = recon4-waveform#display(playable_spectrogram(diff, specs="waveform", output_type='live')) #plot/play the difference spec_graph = audio_spectrogram_image(recon4, justimage=False, db=False, db_range=[-60,20]) display(spec_graph) c =0for thing, name inzip([waveform, recon4, diff],["waveform", "recon", "diff"]): plt.plot(thing[c].cpu().numpy(), alpha=0.5, label=name) plt.legend() plt.show()
Diffusion AutoEncoders
Wrapper for Zach’s DVAE model from September/October. This cannot be subclassed from the above GivenModel class if we want to be able to import the checkpoint files.
This provides an (optional) ‘shorthand’ structure for (some) given_models
Test our autoencoder options
First prepare a waveform and instantiate the various models
print("waveform.shape = ",waveform.shape)waveform_pad = given_model.zero_pad_po2(waveform)print("waveform_pad.shape = ",waveform_pad.shape)# optional: to batch or not to batch?waveform_batch = waveform_pad.unsqueeze(0)print(f"waveform_batch.shape = {waveform_batch.shape}, dtype = {waveform.dtype}")# use reverse order to put most recently-written models diffusion models first, leave out MelSpecgiven_models = [SpectrogramAE(), MagSpectrogramAE(), MagDPhaseSpectrogramAE(), DVAEWrapper(), DMAE1d(),]_ = [x.setup() for x in given_models]
waveform.shape = torch.Size([2, 55728])
waveform_pad.shape = torch.Size([2, 65536])
waveform_batch.shape = torch.Size([1, 2, 65536]), dtype = torch.float32
DVAE: attempting to load checkpoint ~/checkpoints/dvae_checkpoint.ckpt
Checkpoint found!
DMAE1d: attempting to load checkpoint /Users/shawley/checkpoints/dmae1d_checkpoint.ckpt
Checkpoint found!
Sorry, exception = Error(s) in loading state_dict for DMAE1d:
Missing key(s) in state_dict: "resample_encode.kernel", "resample_decode.kernel". . Going with random weights
Now run the waveform through the models:
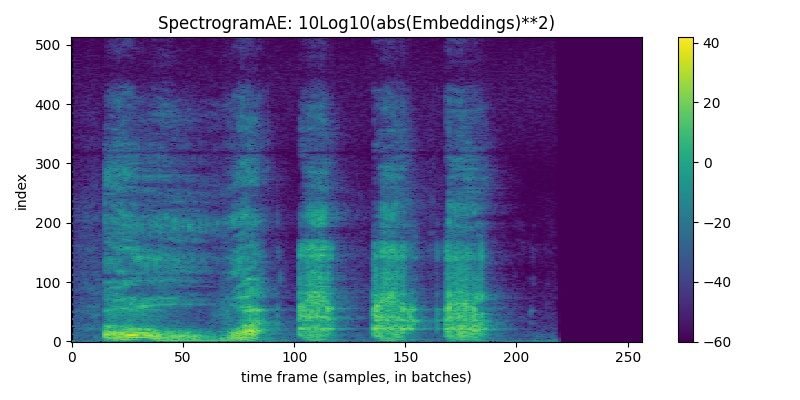
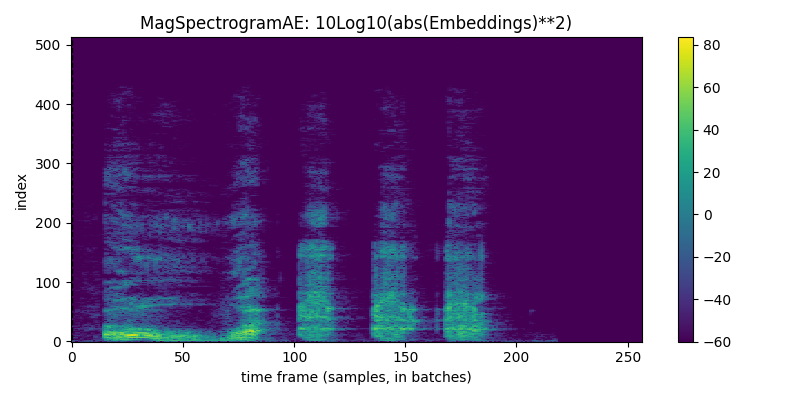
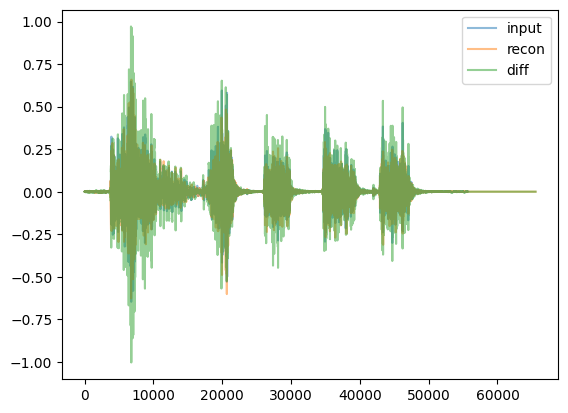
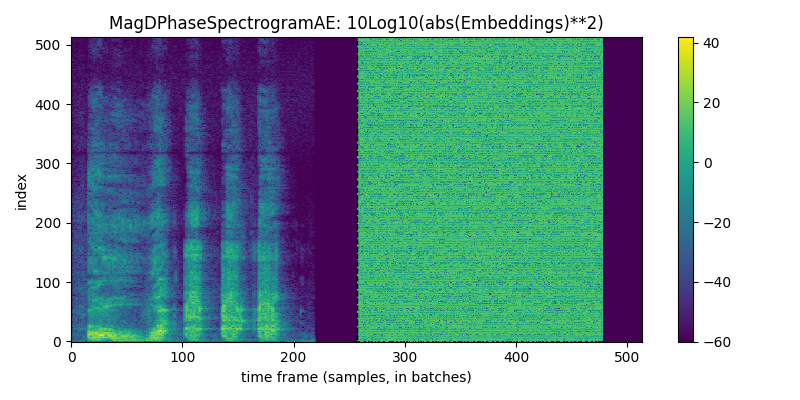
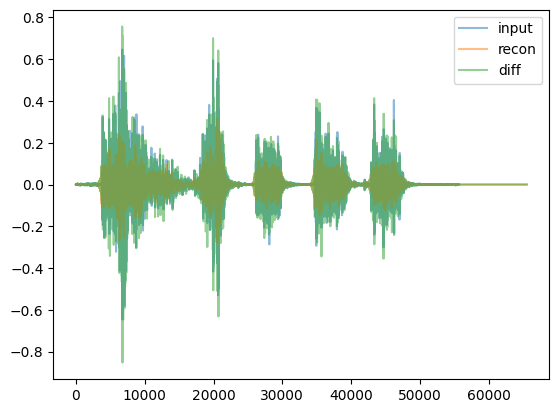
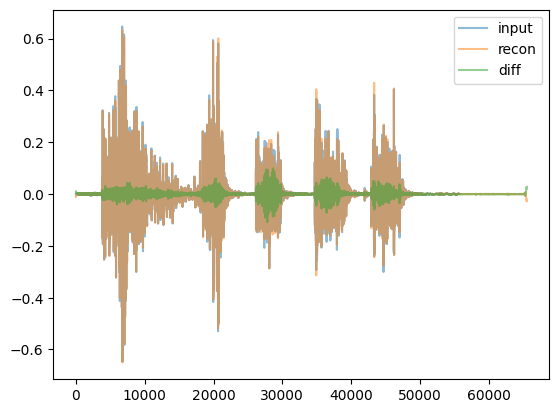
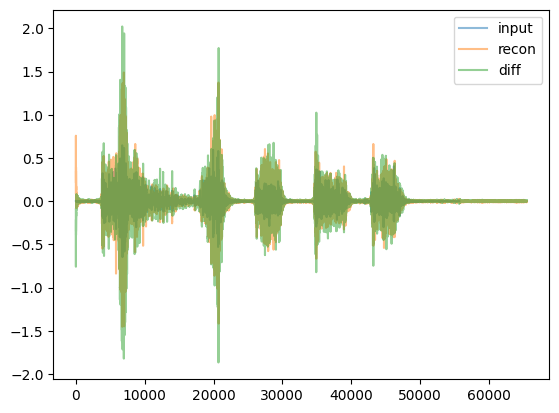
for given_model in given_models: display(HTML('<hr>'))print("given_model.name = ",given_model.name) given_model = given_model.to(device) reps = given_model.encode(waveform_batch.to(device)) recon = given_model.decode(reps) recon = recon.squeeze().cpu()iflen(reps.shape) <4: reps = reps.unsqueeze(0) # for viz purposesprint(f"For model {given_model.name}, reps.shape = {reps.shape} and dtype = {reps.dtype}. recon.shape = {recon.shape}")if given_model.name in ['DVAEWrapper', 'DMAE1d']: title, cmap ='Embeddings', 'coolwarm' vals = reps[:,0,:,:]else: title, cmap =f'{given_model.name}: 10Log10(abs(Embeddings)**2)', 'viridis' vals =10*torch.log10(torch.abs(reps[:,0,:,:])**2+1e-6) display(Audio(recon, rate=48000)) display(tokens_spectrogram_image(vals.cpu(), title=title, mark_batches=True, symmetric=False, cmap=cmap))#THIS NEXT LINE MAKES notebook filesize huge: # display(playable_spectrogram(recon.cpu(), specs="all", output_type='live')) diff = waveform_pad - reconfor thing,name inzip([waveform, recon, diff], ['input','recon','diff']): plt.plot(thing[0,:].numpy(), alpha=0.5, label=name) # just left channel for now plt.legend() plt.show()
given_model.name = SpectrogramAE
For model SpectrogramAE, reps.shape = torch.Size([1, 2, 513, 257]) and dtype = torch.complex64. recon.shape = torch.Size([2, 65536])
given_model.name = MagSpectrogramAE
For model MagSpectrogramAE, reps.shape = torch.Size([1, 2, 513, 257]) and dtype = torch.float32. recon.shape = torch.Size([2, 65536])
given_model.name = MagDPhaseSpectrogramAE
For model MagDPhaseSpectrogramAE, reps.shape = torch.Size([2, 2, 513, 257]) and dtype = torch.float32. recon.shape = torch.Size([2, 65536])
given_model.name = DVAEWrapper
0%| | 0/50 [00:00<?, ?it/s]/Users/shawley/envs/aa/lib/python3.10/site-packages/torch/amp/autocast_mode.py:202: UserWarning: User provided device_type of 'cuda', but CUDA is not available. Disabling
warnings.warn('User provided device_type of \'cuda\', but CUDA is not available. Disabling')
100%|███████████████████████████████████████████████████████████████████████████████████| 50/50 [03:23<00:00, 4.08s/it]
For model DVAEWrapper, reps.shape = torch.Size([1, 1, 64, 512]) and dtype = torch.float32. recon.shape = torch.Size([2, 65536])
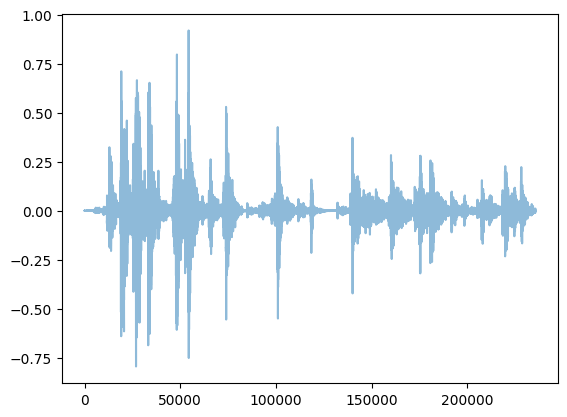
given_model = RAVEWrapper(debug=True)given_model.setup()waveform = load_audio(data_path+'stereo_pewpew.mp3')x =1.5*waveform.clone()[0,:].unsqueeze(0).unsqueeze(0)print("x.shape = ",x.shape)display(Audio(x[0,0,:], rate=48000))#playable_spectrogram(x[0],output_type='live')plt.plot(x[0,0,:].numpy(), alpha=0.5) # just left channel for nowplt.show()
ERROR:root:Path not found: ./v2.gin
ERROR:root:Path not found: /Users/shawley/envs/aa/lib/python3.10/site-packages/rave/./v2.gin
ERROR:root:Path not found: configs/v1.gin
Checkpoint found!
extension = .ts
Resampling ../aeiou/examples/stereo_pewpew.mp3 from 44100.0 Hz to 48000 Hz
x.shape = torch.Size([1, 1, 234505])
z = given_model.encode(x)print("z.shape =",z.shape)tokens_spectrogram_image(z)
y = given_model.decode(z)print("y.shape =",y.shape)display(Audio(y[0,0,:], rate=48000))#playable_spectrogram(y[0,0,:], output_type='live')plt.plot(y[0,0,:].numpy(), alpha=0.5) # just left channel for nowplt.show()