%pip -qq install byol-pytorchNote: you may need to restart the kernel to use updated packages.“In this work, we thus tasked ourselves to find out whether…negative examples are indispensable to prevent collapsing while preserving high performance.” – the BYOL paper
This post is an account of me getting up to speed on Bootstrap Your Own Latent (BYOL), a method for self-supervised learning (SSL) published by the Meta AI team led by Yann LeCun in 2020.
BYOL is not the end-all-be-all of representation learning. While it did outperform earlier methods such as SimCLR, especially on classification tasks, 2020 was a while ago and newer methods have been released by the same group such as 2021’s “Barlow Twins” and “VicReg”, and 2022’s “Masked Siamese ConvNets” and “VICRegL”.
In particular, VICReg seems to be better suited than BYOL for non-classification tasks. Even so, BYOL has been on my mind for a while and it has proven a fruitful place to jump back in to the represenation-learning game.
This post is indebted to
byol-pytorch code repository by Phil Wang aka lucidrainsPreviously, on “Trying to Understand Embeddings, with Scott”, i.e. Part 3 of my blog series, we’d worked out way to think of embeddings, and contrastive losses, and even built a toy model.
In the toy model there were pairwise losses (boo!) and triplet losses (yay!), and even an “Attract Only” option whereby we got rid of ‘repulsion’ entirely. After the “Attract Only” ran, we would rescale the answers and that rescaling would produce a kind of “repulsion”. In that sense, the “Attract Only” method was one way to “remove the contrastive loss” thing.
…uh… but as far as I know, nobody does that. The SimCLR (apparently pronounced “Sim-Clear”) method mentioned in earlier posts is one way of dealing with the problem of finding “challenging” negative examples, by working on a kind of “attraction”, but not as naive as the toy model I made. With SimCLR you don’t enforce similarities on the representations you’re trying to get (which they call \(h\)), rather you map these points via some (nonlinear) “projection” function \(g\) (which they call “projection head”) to some other space and minimize distances between points \(z\) in that space:

The reason they add the projection function \(g\) and don’t just try to maximize similarity between the \(h\) points is because….uh… doing it this way works better in that it frees you of having to mine for hard negatives. That is, earlier methods were already trying to maximize similarity of points \(h_i\) and \(h_j\) in the representation space, and what SimCLR did worked better than that: As in, there’s a graph in the SimCLR paper where they show the accuracy benefits of using the projection head (blue and gold) vs. not doing so (“None”, in green) and the results are striking:
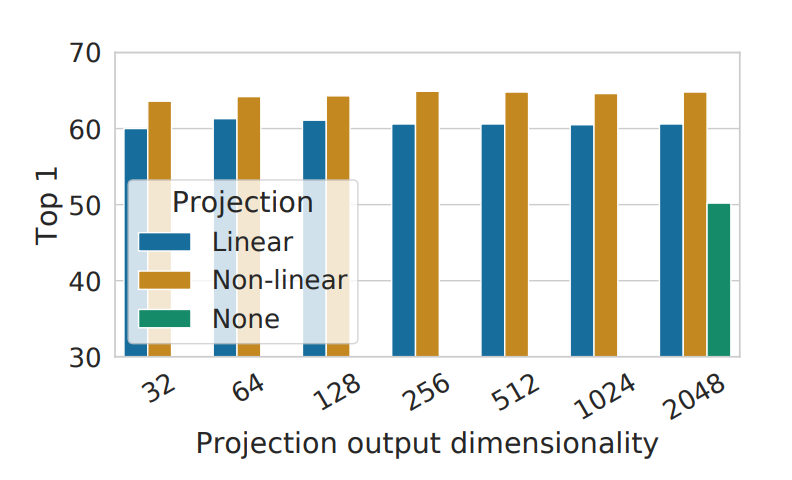
So the “projection head” thing just works. But can it be improved on? Yea. Enter BYOL.
BYOL is another way to simplify ‘contrastive’ learning and avoid hard-negative mining and it seems a bit like “attract only” in that it no longer means explicitly including a respulsive term in the loss function, but BYOL different from SimCLR and not as naive as my own scheme. Instead, BYOL, uses an another network to do some comparisons. With BYOL, we’ll effectively take the SimCLR picture above and also add one more “prediction” function \(q\) to one of the \(z\) points, and then maximize similarity between \(q(z_i)\) and \(z_j\).
Recal that the goal of these systems is to get “good”, “semantically meaningful” representations, however we can. If it takes multiple networks to do that, no worries.
In Part 2 of this blog series, we looked at Siamese Networks, where two copies of the same network are employed for pairwise contrastive learning. With BYOL however, the two networks have the same architectures but different weights, and this difference helps to force “semantically interesting” embedding choices.
Anthropomorphism: The use of two very different networks to try to arrive at similar embedding points is akin to having two very different people talk about something (while each trying on lots of very different funny-colored eyeglasses!) and iteratively refine their understanding through discussion until they can come to (some sufficient level of) agreement.
I’m a firm believer in toy models, so my plan is to use the Fashion-MNIST dataset and then BYOL-embed a 3-dimensional set of represenations that we can look at and play with.
Oh, and since BYOL is a self-supervised method, we’re going to throw away the labels from Fashion-MNIST ;-).
First let’s steal multiple diagrams that all attempt to show the same thing.
From the original BYOL paper, we have this one: 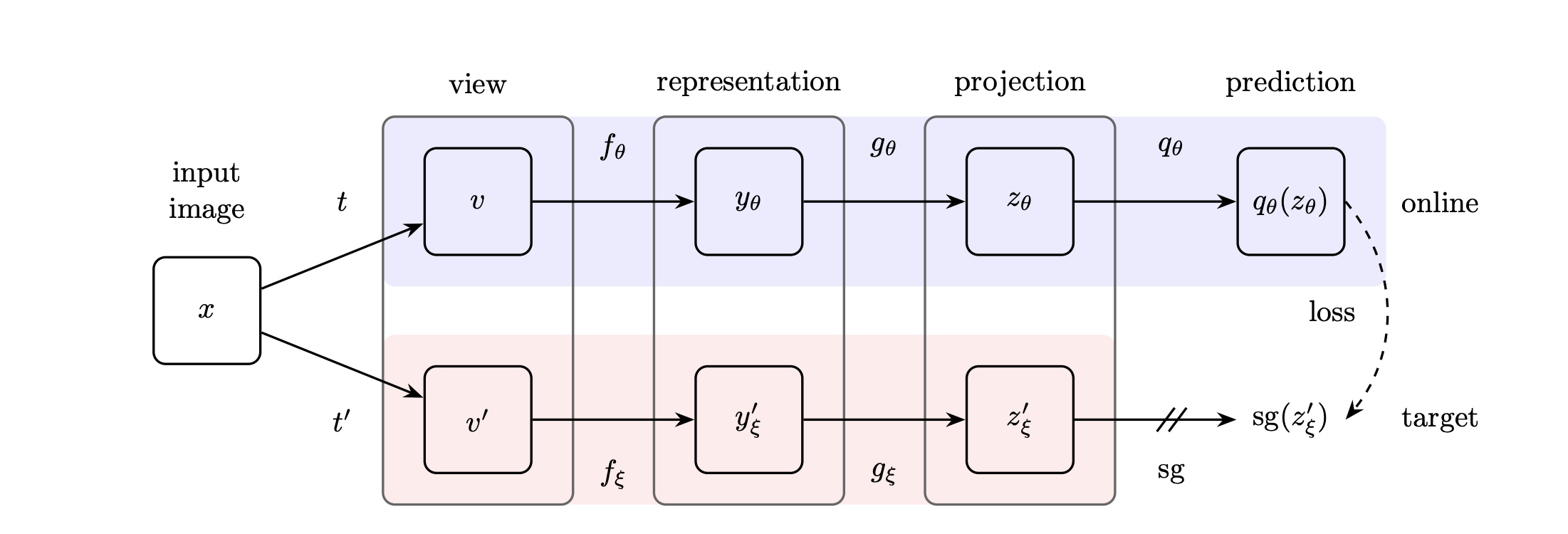
“BYOL’s goal is to learn a representation \(y_\theta\) which can then be used for downstream tasks.” – the BYOL paper.
So beyond the “representation” parts we want to ultimately use, we’ll tack on additional “projection” parts (and even a “prediction” part) to facilitate the training.
Later in the BYOL paper (Figure 8), we have this version: 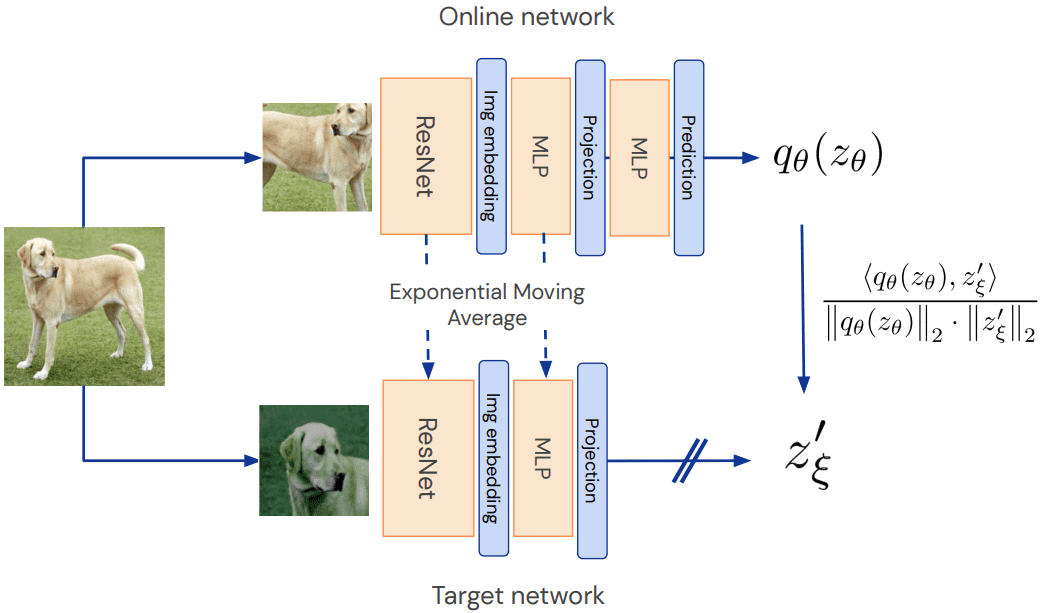
And from the BYOL-A paper we have this version: 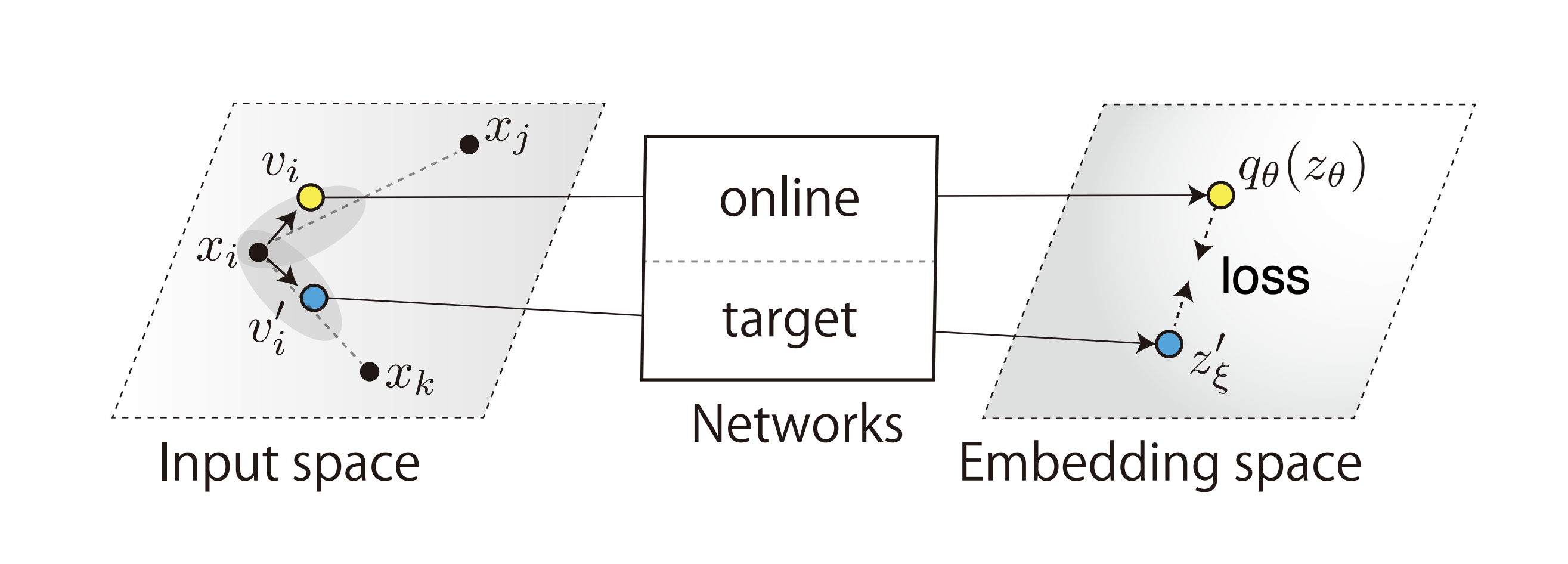
In each case, what we see are 3 main parts:
there is only minimizing, i.e. “attraction” going on. There is no “repulsion”.
Those were broad strokes. What about the details? What about the “exponential moving average” bit, and the \(q_\theta(z_\theta)\) and \(z'_\xi\), and that…equation? We’ll get there.
Note also that we don’t “want to keep” those points \(q_\theta(z_\theta)\) and \(z'_\xi\), they’re just used along the way to help us learn the representations \(y_\theta\).
The two networks aren’t totally different. If you look at the second diagram above (with the dogs), you’ll see that the the first couple layers (in yellow) are of the same types: ResNet then MLP. They don’t have the same weights, but the weights are “related”.
And one of the networks (the “target”) learns “slower” than the other (“online”) network… in a sense. This is the “exponential moving average” (EMA) part. EMA gets used in many contexts in machine learning (ML) to try to help keep things stable so that the system doesn’t jump around too much, i.e. to keep the system from behaving erratically. Think of reinforcement learning, where you want your robot to smoothly improve its position information instead of undergoing wild overcorrections.
In some ML contexts, the slower-learning network is called the “teacher” rather than the “target”, and the “online” network is termed the “student”. Here’s a link for an influential paper on “Teacher-Student” models. I find this terminology to be counter-intutitive because in the BYOL case the “student” would be teaching the “teacher”.
The target network gets its weights only from the EMA of the corresponding weights in the online network. The target weights are not obtained via gradient descent; only the online weights are updated via gradient descent.) In other words, if the online weights are \(\theta\) and the target weights are \(\xi\), then the EMA operation consists of
\[\xi \leftarrow \tau \xi + (1 - \tau) \theta, \] for some choice of the “EMA spread/strength” (hyper)parameter \(\tau\).
The terms “target” and “online” can also refer to the representation “points” in the embedding space. Using such terminology, the BYOL paper explains the method this way:
“the core motivation for BYOL: from a given representation, referred to as target, we can train a new, potentially enhanced representation, referred to as online, by predicting the target representation. From there, we can expect to build a sequence of representations of increasing quality by iterating this procedure, using subsequent online networks as new target networks for further training…”
…i.e. we update the target (a bit, using the EMA) and do it all again.
Ok, so then what’s with the extra “projection” and “prediction” layers?
The BYOL authors use the subscript “\({}_\theta\)” to refer to weights in the online network, and the subscript “\({}_\xi\)” to refer to weights in the target network. Vectors in the target network are also denoted via primes, e.g., \(v'\), \(y'\), \(z'\).
Encoder \(f\) (\(f_\theta\) and \(f_\xi\)): Views (i.e., \(v\) and \(v'\), i.e., augmented versions of the input \(x\)) are mapped to embeddings \(y\) (\(y_\theta\) in the online network) via the “encoder” function \(f\) (\(f_\theta\) online). And remember, “BYOL’s goal is to learn a representation \(y_\theta\) which can then be used for downstream tasks.” For images, \(f\) is typically a ResNet.
Projector \(g\) (\(g_\theta\) and \(g_\xi\)): Maps the embeddings \(y\) to points \(z\) in the space where loss will be evaluated. In particular, \(z'_\xi\) is important because it’s a point output by the target network, which the online network is going to try to “predict”. \(g\) can just be an MLP (though see below for comments about BatchNorm).
Predictor \(q_\theta\): is only on the online network. The predictors output \(q_\theta(z_\theta)\) is the online network’s prediction of the target network’s output \(z'_\xi\).
Why’s the predictor there at all? In other words, why can’t we just compare \(z_\theta\) and \(z'_\xi\) without this additional \(q_\theta\) function?
And for that matter, why can’t we just compare \(y_\theta\) and \(y'_\xi\) directly?
Let’s answer these in reverse order:
But now we’re trying something different, with the goal of avoiding negative examples (i.e. contrastive losses) and the goal of…beating SimCLR. ;-) So bear with this discussion!
We define a loss in the “projected” space between the points \(q_\theta(z_\theta)\) and \(z'_\xi\), that’s just the ordinary mean L2 norm (“Euclidean distance”) between them. So
\[\mathcal{L}_{\theta\xi}= ||\bar{q_{\theta}}(z_\theta) - \bar{z}'_\xi||_2^2\]
Or you can write it in terms of a dot product normalized by the magnitudes, which is what we see written in the BYOL paper:
\[\mathcal{L}_{\theta\xi} = 2 - 2\cdot\frac{\langle q_\theta(z_\theta), z'_\xi \rangle }{\big\|q_\theta(z_\theta)\big\|_2\cdot \big\|z'_\xi\big\|_2 } \]
If that reminds you of a cosine similarity – good, because that’s exactly what it is. See, the graph of \(2(1-\cos x)\) has a nice minimum when its argument is zero, kind of like a parabola on a certain domain:
::: {.cell 0=‘h’ 1=‘i’ 2=‘d’ 3=‘e’}
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-np.pi, np.pi,num=100)
plt.xlabel('x')
plt.ylabel('2 - 2 cos(x)')
plt.plot(x, 2*(1-np.cos(x)))
:::
One other thing they do is to “symmetrize” the loss by also passing \(v'\) through the online network and passing \(v\) through the target network, to compute what they call \(\tilde{\mathcal{L}}_{\xi\theta}\), and then the full loss is the sum of these two losses:
\[\mathcal{L}^{\rm BYOL} = \mathcal{L}_{\theta\xi} + \tilde{\mathcal{L}}_{\xi\theta}\]
In a later post we can talk about writing our own implmentation from scratch (e.g. for something other than images, such as audio). But to just get started with all this, what better place to start a coding implementation than lucidrains’ repository? It’s super easy to install:
%pip -qq install byol-pytorchNote: you may need to restart the kernel to use updated packages.…and we can just “tack it on” to whatever network/task we might have. He provides a sample use case in his README which we’ll modify slightly. First, he sets up a simple test using random images, which we’ll run a version of now:
import torch
from byol_pytorch import BYOL
from torchvision import models, transforms, datasets
from torch.utils.data import DataLoader
from tqdm.notebook import tqdm_notebookresnet = models.resnet50(weights=True) # this will download resnet50 weights.
device = torch.device('cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu')
if torch.device('cpu') == device: print("Warning: Running on the CPU.")
image_size = 28 # size for fashion mnist images
learner = BYOL( # lucidrains' class
resnet,
image_size = image_size,
hidden_layer = 'avgpool'
).to(device)
opt = torch.optim.Adam(learner.parameters(), lr=3e-4)
def sample_unlabelled_images():
return torch.randn(20, 3, image_size, image_size).to(device) # make batch of 20 RGB images from random pixels.
for i in tqdm_notebook(range(50)):
images = sample_unlabelled_images()
loss = learner(images)
opt.zero_grad()
loss.backward()
opt.step()
learner.update_moving_average() # update moving average of target encoderGreat! It works!
Now, rather than using random images, we’ll use Fashion-MNIST. Let’s get the data…
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=transforms.ToTensor()
)
batch_size = 128
train_dataloader = DataLoader(training_data, batch_size=batch_size, shuffle=True)And… we should note that we don’t have to use ResNet50 – in fact, we don’t have to use ResNet-Anything! We could specify some other model, which for our dataset, a very simple model could suffice.
And/or, rather than a classifcation model, we could choose something like a U-Net, and then try to get the “interior” represenation of the U-Net to offer a more interesting represenation than it otherwise might.
For now, just to avoid having to deviate from lucidrains’ demo much, we will stick with pretrained ResNet and just “drop down” in complexity to resnet18:
resnet = models.resnet18(weights=True) # reset resnet weights.
learner = BYOL(
resnet,
image_size=28,
hidden_layer = 'avgpool', # activations from this layer will be used as y_theta!
use_momentum = True # set to false for 'SimSiam' variant. https://arxiv.org/abs/2011.10566
).to(device)
def train_it(learner, lr=3e-4, epochs=5, steps=200):
opt = torch.optim.Adam(learner.parameters(), lr=lr)
for e in range(epochs):
pbar = tqdm_notebook(range(steps), desc=f"Epoch {e}/{epochs}: ")
for i in pbar:
images, labels = next(iter(train_dataloader))
images = images.to(device).tile([1,3,1,1]) # put on GPU & create RGB from greyscale
loss = learner(images)
pbar.set_postfix({'loss':f"{loss.detach():.3g}"})
pbar.refresh()
opt.zero_grad()
loss.backward()
opt.step()
learner.update_moving_average() # update moving average of target encoder
train_it(learner) # operates on learner & resnet in-placeHow do we access and inspect the representations learned from this? lucidrains’ README tells us that we already specified that:
the name (or index) of the hidden layer, whose output is used as the latent representation used for self-supervised training.
…So we specified the layer named “avgpool” as the layer of our network resnet whose activations will serve as our learned representations. We can print out the names of the layers to see where avgpool is (look way near the bottom):
resnetResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)So pretty much all the way at the end, just before the last Linear layer. Let’s see how we can get these layer outputs / activations:
# get some mo' images
images, labels = next(iter(train_dataloader))
images = images.to(device).tile([1,3,1,1]) # put on GPU & create RGB from greyscale
images.shapetorch.Size([128, 3, 28, 28])One way is to use some code we can find in lucidrains’ source code…
reps = learner.online_encoder.get_representation(images)
reps.shapetorch.Size([128, 512])But the ‘classic’ way to do this in PyTorch is to register a “forward hook”, as in:
activation = {}
def get_activation(name):
def hook(model, input, output):
activation[name] = output.detach()
return hook
resnet.avgpool.register_forward_hook(get_activation('avgpool'))
output = resnet(images)
reps = activation['avgpool'].squeeze()
reps.shapetorch.Size([128, 512])Note that our images are 28x28=784 monochrome pixels, so a “representation” via 512 points does not make much of a compression. ….But at this point, you can see the basics of how this works.
I may do a later version of this blog where we write our BYOL code from scratch, and/or use a U-Net or some other architecture, and/or look more closely into BYOL-A, but for now, this seems like a reasonable stopping point. :-)