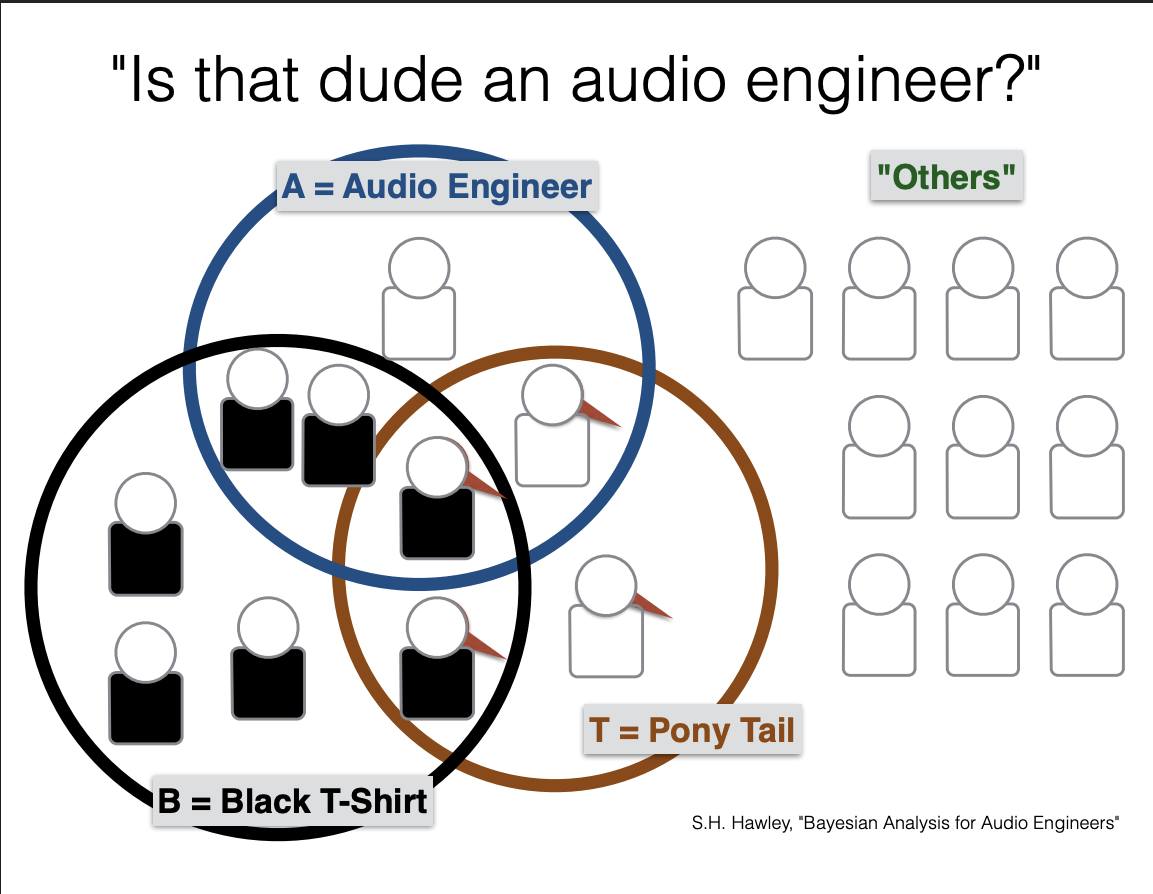
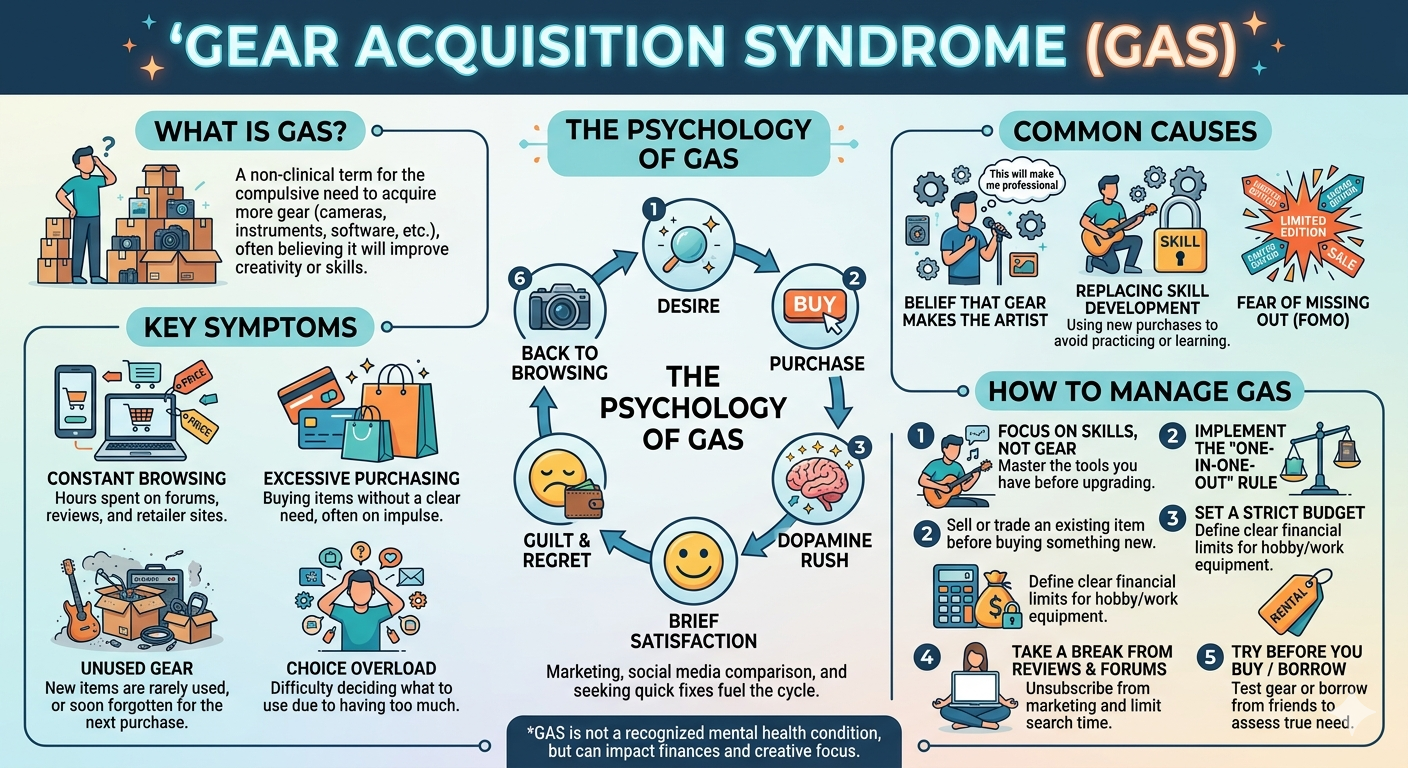
# Did I let Claude generate this code cell? ABSOLUTELY
import json, itertools
from IPython.display import HTML
ROLE_COLORS = {
"treatment": "#c0392b", # dark red
"outcome": "#1e8449", # dark green
"confounder": "#6c3483", # dark purple
"default": "#2471a3", # dark blue
}
_dag_counter = itertools.count()
def show_dag(G, width=600, height=300, node_size=34, font_size=13, title=""):
if not isinstance(G, list):
G, title = [G], [title]
elif not isinstance(title, list):
title = [title] * len(G)
specs = []
divs = []
for g, t in zip(G, title):
nodes = [{"id": str(n), "color": ROLE_COLORS.get(d.get("role"), ROLE_COLORS["default"])}
for n, d in g.nodes(data=True)]
links = [{"source": str(u), "target": str(v), "label": d.get("label", "")}
for u, v, d in g.edges(data=True)]
uid = f"dag{next(_dag_counter)}"
specs.append({"uid": uid, "nodes": nodes, "links": links,
"title": t, "titleOffset": 28 if t else 0})
divs.append(f'<div id="{uid}" style="width:{width}px;height:{height}px;'
f'border:1px solid #444;border-radius:6px;background:#1a1a2e;display:inline-block;"></div>')
specs_json = json.dumps(specs)
container = '<div style="display:flex;gap:12px;flex-wrap:wrap;">' + "".join(divs) + '</div>'
script = f"""
<script type="module">
import * as d3 from "https://cdn.jsdelivr.net/npm/d3@7/+esm";
function initGraphs() {{
const specs = {specs_json};
const W = {width}, H = {height}, R = {node_size}, FS = {font_size};
console.log("initGraphs: found", specs.length, "specs");
for (const spec of specs) {{
const {{uid, nodes, links, title, titleOffset}} = spec;
const el = document.getElementById(uid);
console.log("Looking for #" + uid + ":", el);
if (!el) continue;
const w = W, h = H, r = R, fs = FS;
const svg = d3.select(el).append("svg").attr("width", w).attr("height", h);
if (title) {{
svg.append("text").attr("x", w/2).attr("y", 30) // title placement
.attr("text-anchor", "middle").attr("fill", "#ccc")
.attr("font-size", "18px").attr("font-family", "sans-serif").attr("font-weight", "bold")
.text(title);
}}
svg.append("defs").append("marker")
.attr("id", uid + "-arrow").attr("viewBox", "0 -5 10 10")
.attr("refX", 10).attr("refY", 0).attr("markerWidth", 7).attr("markerHeight", 7).attr("orient", "auto")
.append("path").attr("d", "M0,-5L10,0L0,5").attr("fill", "#aaa");
const linkData = links.map(l => ({{...l}}));
const nodeData = nodes.map(n => ({{...n}}));
const sim = d3.forceSimulation(nodeData)
.force("link", d3.forceLink(linkData).id(d => d.id).distance(140))
.force("charge", d3.forceManyBody().strength(-500))
.force("center", d3.forceCenter(w/2, titleOffset/2 + h/2));
const link = svg.append("g").selectAll("line").data(linkData).join("line")
.attr("stroke", "#aaa").attr("stroke-width", 2)
.attr("marker-end", "url(#" + uid + "-arrow)");
const edgeLabels = svg.append("g").selectAll("text").data(linkData.filter(d => d.label)).join("text")
.attr("text-anchor", "middle").attr("fill", "#ffdd57")
.attr("font-size", "16px").attr("font-family", "sans-serif").attr("font-weight", "bold")
.text(d => d.label);
const node = svg.append("g").selectAll("g").data(nodeData).join("g")
.call(d3.drag()
.on("start", (e,d) => {{ if (!e.active) sim.alphaTarget(0.3).restart(); d.fx=d.x; d.fy=d.y; }})
.on("drag", (e,d) => {{ d.fx=e.x; d.fy=e.y; }})
.on("end", (e,d) => {{ if (!e.active) sim.alphaTarget(0); d.fx=null; d.fy=null; }}));
node.append("circle").attr("r", r).attr("fill", d => d.color).attr("stroke", "#fff").attr("stroke-width", 1.5);
node.each(function(d) {{
const lines = d.id.split("\\n");
const txt = d3.select(this).append("text").attr("text-anchor", "middle")
.attr("fill", "white").attr("font-size", fs+"px").attr("font-family", "sans-serif");
const lh = fs * 1.2, yStart = -((lines.length - 1) * lh) / 2;
lines.forEach((line, i) => {{
txt.append("tspan").attr("x", 0).attr("y", yStart + i*lh).attr("dy", "0.35em").text(line);
}});
}});
sim.on("tick", () => {{
link.each(function(d) {{
const dx = d.target.x-d.source.x, dy = d.target.y-d.source.y;
const dist = Math.sqrt(dx*dx+dy*dy) || 1, ux = dx/dist, uy = dy/dist;
d3.select(this)
.attr("x1", d.source.x+ux*r).attr("y1", d.source.y+uy*r)
.attr("x2", d.target.x-ux*r).attr("y2", d.target.y-uy*r);
}});
edgeLabels
.attr("x", d => (d.source.x+d.target.x)/2)
.attr("y", d => (d.source.y+d.target.y)/2 - 8);
node.attr("transform", d => `translate(${{d.x}},${{d.y}})`);
}});
}}
}}
setTimeout(initGraphs, 100);
</script>
"""
return HTML(container + script)
show_dag([G, G2], width=330, height=320, title=["Gear Acquisition Syndrome", "Reality"])