import numpy as np, matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.update({'xlabel':'x', 'ylabel':'f'})
x = np.arange(-5,7,0.1)
ax.plot(x,(x-1)**2+1)
plt.show()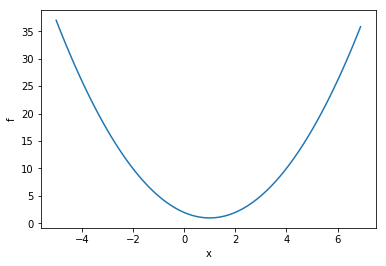
Image credit: NASA
By the end of this session, we will – as an example problem – have used the 1-dimensional path of an object in the presesece of gravity, to ‘train’ a system to correctly infer (i.e. to ‘learn’) the constants of the motion – initial position and velocity, and the acceleration due to gravity. Hopefully we learn a few other things along the way. ;-)
In the next installment, “Part Ib,” we’ll derive the differential equation of motion, and in then in “Part II” we’ll adapt the techniques we’ve learned here to do signal processing.
Let’s put the “sample problem” aside for now, and talk about the general problem of optimization. Often we may wish to minimize some function \(f(x)\). In science, doing so may enable us to fit a curve to our data, as we’ll do below. Similarly,‘machine learning’ systems often operate on the basis of minimizing a ‘cost’ function to discern patterns in complex datasets.
Thus we want to find the value of \(x\) for which \(f(x)\) is the smallest. A graph of such a function might look like this…
(Python code follows, to make the graph)
import numpy as np, matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.update({'xlabel':'x', 'ylabel':'f'})
x = np.arange(-5,7,0.1)
ax.plot(x,(x-1)**2+1)
plt.show()
If \(f(x)\) is differentiable and the derivative (i.e., slope) \(df/dx\) can be evaluated easily, then we can perform a so-called “gradient descent”.
We do so as follows:
A nice feature of this method is that as \(df/dx \rightarrow 0\), so too \(\Delta x\rightarrow0\). So an “adaptive stepsize” is built-in.
Now let’s try this out with some Python code…
from __future__ import print_function # for backwards-compatibility w/ Python2
import numpy as np, matplotlib.pyplot as plt
def f(x):
return (x-1)**2+1
def dfdx(x):
return 2*(x-1)
fig, ax = plt.subplots()
ax.update({'xlabel':'x', 'ylabel':'f'})
x = np.arange(-5,7,0.1)
ax.plot(x,f(x),ls='dashed')
for alpha in ([0.002,0.1,0.25,0.8]):
print("alpha = ",alpha)
x = -5 # starting point
x_arr = [x]
y_arr = [f(x)]
maxiter = 50
for iter in range(maxiter): # do the descent
# these two lines are just for plotting later
x_arr.append(x)
y_arr.append( f(x) )
# Here's the important part: update via gradient descent
x = x - alpha * dfdx(x)
# report and make the plot
print(" final x = ",x)
ax.plot(x_arr,y_arr,'o-',label="alpha = "+str(alpha))
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles, labels)
plt.show()alpha = 0.002
final x = -3.910414704056598
alpha = 0.1
final x = 0.9999143651384377
alpha = 0.25
final x = 0.9999999999999947
alpha = 0.8
final x = 0.999999999951503
Notice how the larger learning rate (\(\alpha\)=0.8) meant that the steps taken were so large that they “overshot” the minimum, whereas the too-small learning rate (\(\alpha=0.002\)) still hadn’t come anywhere close to the minimum before the maximum iteration was reached.
Exercise: Experiment by editing the above code: Try different learning rates and observe the behavior.
You may have noticed, if you made the learning rate too large, that the algorithm does not converge to the solution but instead ‘blows up’. This is the ‘flip side’ of the ‘adaptive step size’ feature of this algorithm: If you jump “across” the minimum to the other side and end up a greater distance from the minimum that where you started, you will encounter an even larger gradient, which will lead to an even larger \(\Delta x\), and so on.
We can see this with the same code from before, let’s just use a different starting point and a step size that’s clearly too large…
from __future__ import print_function # for backwards-compatibility w/ Python2
import numpy as np, matplotlib.pyplot as plt
def f(x):
return (x-1)**2+1
def dfdx(x):
return 2*(x-1)
alpha = 1.1 # "too big" learning rate
print("alpha = ",alpha)
x = -1 # starting point
x_arr = []
y_arr = []
maxiter = 12
for iter in range(maxiter): # do the descent
x_arr.append(x)
y_arr.append( f(x) )
x = x - alpha * dfdx(x)
# report and make the plot
print(" final x = ",x)
fig, ax = plt.subplots()
ax.update({'xlabel':'x', 'ylabel':'f'})
plt.plot(x_arr,y_arr,'r',zorder=2,)
plt.scatter(x_arr,y_arr,zorder=3,c=range(len(x_arr)),cmap=plt.cm.viridis)
xlim = ax.get_xlim() # find out axis limits
x = np.arange(xlim[0],xlim[1],1) # dashed line
plt.plot(x,f(x),zorder=1,ls='dashed')
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles, labels)
plt.show()alpha = 1.1
final x = -16.83220089651204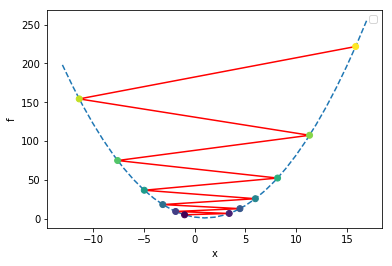
In the above plot, we colored the points by iteration number, starting with the dark purple at the initial location of x=-1, and bouncing around ever-farther from the solution as the color changes to yellow. As this happens, the error is growing exponentially; this is one example of a numerical instability. Thus, this algorithm is not entirely stable.

One way to guard against this to check: is our value of \(f(x)\) at the current iteration larger than the value it was at the previous iteration? If so, that’s a sign that our learning rate is too large, and we can use this criterion to dynamically adjust the learning rate.
Let’s add some ‘control’ code to that effect, to the previous script, and also print out the values of the relevant variables so we can track the progress:
from __future__ import print_function # for backwards-compatibility w/ Python2
import numpy as np, matplotlib.pyplot as plt
def f(x):
return (x-1)**2+1
def dfdx(x):
return 2*(x-1)
alpha = 13.0 # "too big" learning rate
print("alpha = ",alpha)
x = -1 # starting point
x_arr = []
y_arr = []
maxiter = 20
f_old = 1e99 # some big number
for iter in range(maxiter): # do the descent
# these two lines are just for plotting later
x_arr.append(x)
f_cur = f(x)
y_arr.append( f_cur )
print("iter = ",iter,"x = ",x,"f(x) =",f(x),"alpha = ",alpha)
if (f_cur > f_old): # check for runaway behavior
alpha = alpha * 0.5
print(" decreasing alpha. new alpha = ",alpha)
f_old = f_cur
# update via gradient descent
x = x - alpha * dfdx(x)
# report and make the plot
print(" final x = ",x)
fig, ax = plt.subplots()
ax.update({'xlabel':'x', 'ylabel':'f'})
plt.plot(x_arr,y_arr,'r',zorder=2,)
plt.scatter(x_arr,y_arr,zorder=3,c=range(len(x_arr)),cmap=plt.cm.viridis)
xlim = ax.get_xlim()
x = np.arange(xlim[0],xlim[1],1) # x for dashed line
plt.plot(x,f(x),zorder=1,ls='dashed')
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles, labels)
plt.show()alpha = 13.0
iter = 0 x = -1 f(x) = 5 alpha = 13.0
iter = 1 x = 51.0 f(x) = 2501.0 alpha = 13.0
decreasing alpha. new alpha = 6.5
iter = 2 x = -599.0 f(x) = 360001.0 alpha = 6.5
decreasing alpha. new alpha = 3.25
iter = 3 x = 3301.0 f(x) = 10890001.0 alpha = 3.25
decreasing alpha. new alpha = 1.625
iter = 4 x = -7424.0 f(x) = 55130626.0 alpha = 1.625
decreasing alpha. new alpha = 0.8125
iter = 5 x = 4641.625 f(x) = 21535401.390625 alpha = 0.8125
iter = 6 x = -2899.390625 f(x) = 8412266.77758789 alpha = 0.8125
iter = 7 x = 1813.744140625 f(x) = 3286042.31937027 alpha = 0.8125
iter = 8 x = -1131.965087890625 f(x) = 1283610.8903790116 alpha = 0.8125
iter = 9 x = 709.1031799316406 f(x) = 501411.1134293014 alpha = 0.8125
iter = 10 x = -441.5644874572754 f(x) = 195864.32555832085 alpha = 0.8125
iter = 11 x = 277.6028046607971 f(x) = 76510.1115462191 alpha = 0.8125
iter = 12 x = -171.8767529129982 f(x) = 29887.37169774183 alpha = 0.8125
iter = 13 x = 109.04797057062387 f(x) = 11675.363944430403 alpha = 0.8125
iter = 14 x = -66.52998160663992 f(x) = 4561.298415793126 alpha = 0.8125
iter = 15 x = 43.20623850414995 f(x) = 1782.36656866919 alpha = 0.8125
iter = 16 x = -25.37889906509372 f(x) = 696.8463158864023 alpha = 0.8125
iter = 17 x = 17.486811915683575 f(x) = 272.8149671431259 alpha = 0.8125
iter = 18 x = -9.304257447302234 f(x) = 107.17772154028356 alpha = 0.8125
iter = 19 x = 7.440160904563896 f(x) = 42.47567247667326 alpha = 0.8125
final x = -3.025100565352435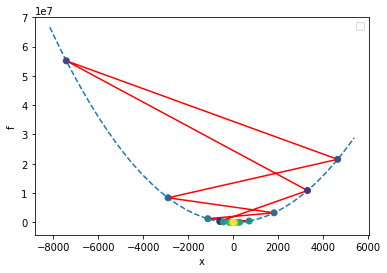
So in the preceding example, we start at \(x=-1\), then the unstable behavior starts and we begin diverging from the minimum, so we decrease \(\alpha\) as often as our criterion tells us to. Finally \(\alpha\) becomes low enought to get the system ‘under control’ and the algorithm enters the convergent regime.
Exercise: In the example above, we only decrease \(\alpha\) by a factor of 2 each time, but it would be more efficient to decrease by a factor of 10. Try that and observe the behavior of the system.
You may say, “Why do I need to worry about this instability stuff? As long as \(\alpha<1\) the system will converge, right?” Well, for this simple system it seems obvious what needs to happen, but with multidimensional optimization problems (see below), it’s not always obvious what to do. (Sometimes different ‘dimensions’ need different learning rates.) This simple example serves as an introduction to phenomena which arise in more complex situations.
To explore more complicated functions, we’re going to take advantage of the SymPy package, to let it take derivatives for us. Try executing the import in the next cell, and if nothing happens it means you have SymPy installed. If you get an error, you may need to go into a Terminal and run “pip install sympy”.
import sympyYou’re good? No errors? Ok, moving on…
from __future__ import print_function # for backwards-compatibility w/ Python2
import numpy as np, matplotlib.pyplot as plt
from sympy import Symbol, diff
x = Symbol('x')
# our function, more complicated (SymPy handles it!)
f = (x-1)**4 - 20*(x-1)**2 + 10*x + 1
dfdx = diff(f,x)
# setup
fig, ax = plt.subplots()
ax.update({'xlabel':'x', 'ylabel':'f'})
x_arr = np.arange(-5,7,0.1)
y_arr = np.copy(x_arr)
for i, val in enumerate(x_arr):
y_arr[i] = f.evalf(subs={x:val})
ax.plot(x_arr,y_arr,ls='dashed') # space of 'error function'
# for a variety of learning rates...
for alpha in ([0.002,0.01,0.03]):
print("alpha = ",alpha)
xval = 6 # starting point
x_arr = [xval]
y_arr = [f.evalf(subs={x:xval})]
maxiter = 50
# do the descent
for iter in range(maxiter):
# these two lines are just for plotting later
x_arr.append(xval)
y_arr.append( f.evalf(subs={x:xval}) )
# update via gradient descent
xval = xval - alpha * dfdx.evalf(subs={x:xval})
print(" final xval = ",xval)
ax.plot(x_arr,y_arr,'o-',label="alpha = "+str(alpha))
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles, labels)
plt.show()alpha = 0.002
final xval = 4.02939564594151
alpha = 0.01
final xval = 4.02896613891181
alpha = 0.03
final xval = -2.00328879556504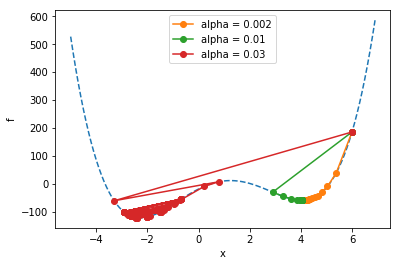
All the runs start at \(x=6\). Notice how the runs marked in organge and green go on to find a “local” minimum, but they don’t find the “global” minimum (the overall lowest point) like the run marked in red does. The problem of ending up at non-global local minima is a generic problem for all kinds of optimization tasks. It tends to get even worse when you add more parameters…
(A descent into darkness…)
Let’s define a function of two variables, that’s got at least one minimum in it. We’ll choose \[f(x,y) = -\left( \cos x + 3\cos y \right) /2,\] which actually has infinitely many minima, but we’ll try to ‘zoom in’ on just one.
We can vizualize this function via the graph produced by the code below; in the graph, darker areas show lower values than ligher areas, and there is a minimum at the point \(x=0,y=0\) where \(f(0,0)=-2\).
import numpy as np, matplotlib.pyplot as plt
def f(x,y):
return -( np.cos(x) + 3*np.cos(y) )/2
x = y = np.linspace(-4, 4, 100)
z = np.zeros([len(x), len(y)])
for i in range(len(x)):
for j in range(len(y)):
z[j, i] = f(x[i], y[j])
fig, ax = plt.subplots()
ax.update({'xlabel':'x', 'ylabel':'y'})
cs = ax.pcolor(x, y, z, cmap=plt.cm.afmhot)
plt.gca().set_aspect('equal', adjustable='box')
cbar = fig.colorbar(cs, orientation='vertical')
plt.show()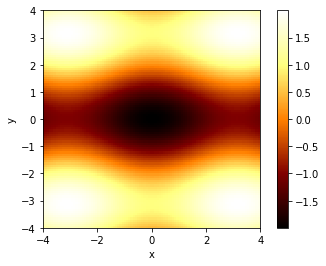
The way we find a minimum is similar to what we did before, except we use partial derivatives in the x- and y-directions:
\[x_{new} = x_{old} + \Delta x,\ \ \ \ \ \ \Delta x = - \alpha {\partial f\over \partial x} \] \[y_{new} = y_{old} + \Delta y,\ \ \ \ \ \ \Delta y = - \alpha {\partial f\over \partial y},\]
from __future__ import print_function # for backwards-compatibility w/ Python2
import numpy as np, matplotlib.pyplot as plt
# our function
def f(x,y):
return -( np.cos(x) + 3*np.cos(y) )/2
def dfdx(x,y):
return np.sin(x)/2
def dfdy(x,y):
return 3*np.sin(y)/2
# variables for this run
alpha = 0.5
xval, yval = 2.5, 1.5 # starting guess(es)
x_arr = []
y_arr = []
maxiter = 20
for iter in range(maxiter): # gradient descent loop
x_arr.append(xval)
y_arr.append(yval)
xval = xval - alpha * dfdx(xval,yval)
yval = yval - alpha * dfdy(xval,yval)
print("Final xval, yval = ",xval,yval,". Target is (0,0)")
# background image: plot the color background
x = y = np.linspace(-4, 4, 100)
z = np.zeros([len(x), len(y)])
for i in range(len(x)):
for j in range(len(y)):
z[j, i] = f(x[i], y[j])
fig, ax = plt.subplots()
ax.update({'xlabel':'x', 'ylabel':'y'})
cs = ax.pcolor(x, y, z, cmap=plt.cm.afmhot)
plt.gca().set_aspect('equal', adjustable='box')
cbar = fig.colorbar(cs, orientation='vertical')
# plot the progress of our optimization
plt.plot(x_arr,y_arr,zorder=1)
plt.scatter(x_arr,y_arr,zorder=2,c=range(len(x_arr)),cmap=plt.cm.viridis)
handles, labels = ax.get_legend_handles_labels()
plt.show()Final xval, yval = 0.0272555602238 3.59400699273e-12 . Target is (0,0)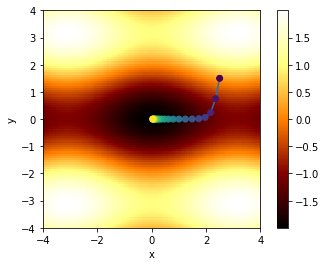
In the above figure, we’ve shown the ‘path’ the algorithm takes in \(x\)-\(y\) space, coloring the dots according to iteration number, so that the first points are dark purple, and later points tend to yellow.
Note that due to the asymmetry in the function (between \(x\) and \(y\)), the path descends rapidly in \(y\), and then travels along the “valley” in \(x\) to reach the minimum. This “long narrow valley” behavior is common in multidimensional optimization problems: the system may ‘solve’ one parameter quickly, but require thousands of operations to find the other one.
Many sophisticated schemes have arisen to handle this challenge, and we won’t cover them here. For now, suffice it to say that, yes, this sort of thing happens. You may have ‘found’ highly accurate values for certain parameters, but others are bogging down the process of convergence.
Next time, we’ll cover a common application of optimization: Least Squares Regression…
This is such a common thing to do in science and statistics, that everyone should learn how it works. We’ll do it for linear relationships, but it generalizes to nonlinear situations as well.
Let’s say we’re trying to fit a line to a bunch of data. We’ve been given \(n\) data points with coordinates \((x_i,y_i)\) where \(i=1..n\). The problem becomes, given a line \(f(x) = mx+b\), find the values of the parameters \(m\) and \(b\) which minimize the overall “error”.
The error can take many forms; one is the squared error \(SE\), which is just the sum of the squares of the “distances” between each data point’s \(y\)-value and the “guess” from the line fit \(f\) at each value of \(x\):
\[ SE = (f(x_1) - y_1)^2 + (f(x_2) - y_2)^2 + ... (f(x_n)-y_n)^2,\]
We can write this concisely as \[ SE = \sum_{i=1}^n (f(x_i)-y_i)^2.\]
Another popular form is the “mean squared error” \(MSE\), which is just \(SE/n\):
\[ MSE = {1\over n}\sum_{i=1}^n (f(x_i)-y_i)^2.\]
The MSE has the nice feature that as you add more data points, it tends to hold a more-or-less consistent value (as opposed to the SE which gets bigger as you add more points). We’ll use the MSE in the work that follows.
So expanding out \(f(x)\), we see that the MSE is a function of \(m\) and \(b\), and these are the parameters we’ll vary to minimize the MSE: \[ MSE(m,b) = {1\over n}\sum_{i=1}^n (mx_i+b-y_i)^2.\]
So, following our earlier work on multidimensional optimization, we start with guesses for \(m\) and \(b\) and then update according to gradient descent:
\[m_{new} = m_{old} + \Delta m,\ \ \ \ \ \ \Delta m = -\alpha{\partial (MSE)\over\partial m} = -\alpha{2\over n}\sum_{i=1}^n (mx_i+b-y_i)(x_i) \] \[b_{new} = b_{old} + \Delta b,\ \ \ \ \ \ \Delta b = -\alpha{\partial (MSE)\over\partial b} = -\alpha{2\over n}\sum_{i=1}^n (mx_i+b-y_i)(1).\]
So, to start off, let’s get some data…
# Set up the input data
n = 20
np.random.seed(1) # for reproducability
x_data = np.random.uniform(size=n) # random points for x
m_exact = 2.0
b_exact = 1.5
y_data = m_exact * x_data + b_exact
y_data += 0.3*np.random.normal(size=n) # add noise
# Plot the data
def plot_data(x_data, y_data, axis_labels=('x','y'), zero_y=False):
fig, ax = plt.subplots()
ax.update({'xlabel':axis_labels[0], 'ylabel':axis_labels[1]})
ax.plot(x_data, y_data,'o')
if (zero_y):
ax.set_ylim([0,ax.get_ylim()[1]*1.1])
plt.show()
plot_data(x_data,y_data, zero_y=True)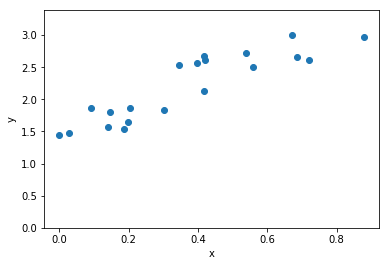
Note: in contrast to earlier parts of this document which include complete python programs in every code post, for brevity’s sake we will start using the notebook “as intended”, relying on the internal state and adding successive bits of code which make use of the “memory” of previously-defined variables.
Let’s map out the MSE for this group of points, as a function of possible \(m\) and \(b\) values…
# map out the MSE for various values of m and b
def MSE(x,y,m,b):
# Use Python array operations to compute sums
return ((m*x + b - y)**2).mean()
mm = bb = np.linspace(0, 4, 50)
z = np.zeros([len(mm), len(bb)])
for i in range(len(mm)):
for j in range(len(bb)):
z[j, i] = MSE(x_data,y_data, mm[i],bb[j])
fig, ax = plt.subplots()
ax.update({'xlabel':'m', 'ylabel':'b'})
cs = ax.pcolor(mm, bb, np.log(z), cmap=plt.cm.afmhot)
plt.gca().set_aspect('equal', adjustable='box')
plt.show()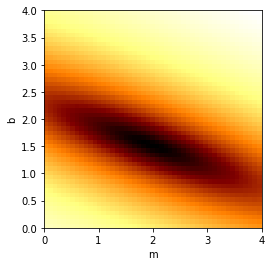
We see the minimum near the “exact” values chosen in the begininng. (Note that we’ve plotted the logarithm of the MSE just to make the colors stand out better.)
Next we will choose starting guesses for \(m\) and \(b\), and use gradient descent to fit the line…
m = 3.5 # initial guess
b = 3.5
m_arr = []
b_arr = []
def dMSEdm(x,y,m,b):
return (2*(m*x + b - y) *x).mean()
def dMSEdb(x,y,m,b):
return (2*(m*x + b - y)).mean()
alpha = 0.1
maxiter, printevery = 500, 4
for iter in range(maxiter):
m_arr.append(m)
b_arr.append(b)
if (0 == iter % printevery):
print(iter,": b, m = ",b,m,", MSE = ",MSE(x_data,y_data,m,b))
m = m - alpha * dMSEdm(x_data,y_data,m,b)
b = b - alpha * dMSEdb(x_data,y_data,m,b)
print("Final result: m = ",m,", b = ",b)
# background image: plot the color background (remembered from before)
fig, ax = plt.subplots()
ax.update({'xlabel':'m', 'ylabel':'b'})
cs = ax.pcolor(mm, bb, np.log(z), cmap=plt.cm.afmhot)
plt.gca().set_aspect('equal', adjustable='box')
# plot the progress of our descent
plt.plot(m_arr,b_arr,zorder=1)
plt.scatter(m_arr,b_arr,zorder=2,c=range(len(m_arr)),cmap=plt.cm.viridis)
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles, labels)
plt.show()0 : b, m = 3.5 3.5 , MSE = 6.86780331186
4 : b, m = 2.07377614457 2.89890882764 , MSE = 0.98222306593
8 : b, m = 1.55966423863 2.66310750082 , MSE = 0.194874325956
12 : b, m = 1.37811928553 2.56128194633 , MSE = 0.0877947061277
16 : b, m = 1.31767685375 2.50899769214 , MSE = 0.0718728682069
20 : b, m = 1.30118421505 2.47541762467 , MSE = 0.0683627241086
24 : b, m = 1.30049838878 2.44926336309 , MSE = 0.0666665839706
28 : b, m = 1.30535957938 2.4263945595 , MSE = 0.0653286635918
32 : b, m = 1.3120331485 2.40527655618 , MSE = 0.0641346050201
36 : b, m = 1.31916510087 2.38532649645 , MSE = 0.0630441987699
40 : b, m = 1.32626977167 2.36630978168 , MSE = 0.0620438837066
44 : b, m = 1.33317800067 2.34811979986 , MSE = 0.0611251920416
48 : b, m = 1.33983578596 2.33069751134 , MSE = 0.0602811821983
52 : b, m = 1.34623082683 2.31400206963 , MSE = 0.059505695069
56 : b, m = 1.35236573256 2.29800006645 , MSE = 0.0587931380437
60 : b, m = 1.35824825911 2.28266157418 , MSE = 0.0581383942813
64 : b, m = 1.36388775858 2.26795866993 , MSE = 0.0575367695918
68 : b, m = 1.3692938954 2.2538648666 , MSE = 0.0569839532221
72 : b, m = 1.374476189 2.2403548761 , MSE = 0.0564759850457
76 : b, m = 1.37944385765 2.22740449497 , MSE = 0.0560092265247
80 : b, m = 1.3842057718 2.21499053585 , MSE = 0.0555803344137
84 : b, m = 1.38877044688 2.20309077677 , MSE = 0.0551862367311
88 : b, m = 1.39314605011 2.19168391801 , MSE = 0.0548241107275
92 : b, m = 1.39734041211 2.18074954278 , MSE = 0.0544913626571
96 : b, m = 1.4013610397 2.17026808021 , MSE = 0.054185609197
100 : b, m = 1.40521512901 2.16022077017 , MSE = 0.0539046603748
104 : b, m = 1.40890957817 2.1505896296 , MSE = 0.0536465038826
108 : b, m = 1.41245099963 2.14135742035 , MSE = 0.0534092906637
112 : b, m = 1.41584573193 2.1325076183 , MSE = 0.0531913216685
116 : b, m = 1.41909985108 2.12402438375 , MSE = 0.0529910356848
120 : b, m = 1.42221918141 2.11589253313 , MSE = 0.0528069981559
124 : b, m = 1.42520930601 2.10809751176 , MSE = 0.0526378909052
128 : b, m = 1.42807557671 2.10062536785 , MSE = 0.052482502695
132 : b, m = 1.43082312365 2.09346272749 , MSE = 0.0523397205507
136 : b, m = 1.4334568645 2.08659677074 , MSE = 0.0522085217891
140 : b, m = 1.43598151321 2.08001520867 , MSE = 0.0520879666937
144 : b, m = 1.43840158849 2.07370626138 , MSE = 0.0519771917836
148 : b, m = 1.44072142187 2.0676586369 , MSE = 0.0518754036286
152 : b, m = 1.44294516546 2.06186151097 , MSE = 0.051781873167
156 : b, m = 1.44507679941 2.0563045077 , MSE = 0.0516959304829
160 : b, m = 1.44712013898 2.05097768097 , MSE = 0.0516169600082
164 : b, m = 1.44907884142 2.04587149665 , MSE = 0.0515443961135
168 : b, m = 1.45095641248 2.04097681551 , MSE = 0.0514777190569
172 : b, m = 1.45275621269 2.03628487687 , MSE = 0.0514164512613
176 : b, m = 1.45448146341 2.03178728296 , MSE = 0.0513601538933
180 : b, m = 1.45613525255 2.0274759838 , MSE = 0.0513084237208
184 : b, m = 1.45772054011 2.0233432629 , MSE = 0.0512608902243
188 : b, m = 1.4592401635 2.01938172337 , MSE = 0.051217212943
192 : b, m = 1.4606968426 2.0155842747 , MSE = 0.0511770790366
196 : b, m = 1.46209318462 2.01194412009 , MSE = 0.0511402010444
200 : b, m = 1.46343168877 2.00845474426 , MSE = 0.0511063148261
204 : b, m = 1.46471475077 2.00510990182 , MSE = 0.0510751776703
208 : b, m = 1.46594466707 2.00190360604 , MSE = 0.0510465665558
212 : b, m = 1.46712363904 1.99883011819 , MSE = 0.0510202765543
216 : b, m = 1.46825377682 1.99588393722 , MSE = 0.0509961193626
220 : b, m = 1.46933710318 1.99305978998 , MSE = 0.0509739219537
224 : b, m = 1.4703755571 1.99035262169 , MSE = 0.0509535253378
228 : b, m = 1.47137099724 1.98775758697 , MSE = 0.0509347834233
232 : b, m = 1.47232520527 1.98527004115 , MSE = 0.0509175619703
236 : b, m = 1.47323988906 1.98288553192 , MSE = 0.0509017376297
240 : b, m = 1.47411668575 1.98059979141 , MSE = 0.0508871970587
244 : b, m = 1.47495716466 1.97840872852 , MSE = 0.0508738361101
248 : b, m = 1.4757628301 1.97630842161 , MSE = 0.0508615590853
252 : b, m = 1.47653512409 1.97429511148 , MSE = 0.0508502780498
256 : b, m = 1.47727542891 1.97236519463 , MSE = 0.0508399122026
260 : b, m = 1.47798506956 1.97051521684 , MSE = 0.050830387298
264 : b, m = 1.47866531621 1.96874186695 , MSE = 0.0508216351133
268 : b, m = 1.47931738637 1.96704197096 , MSE = 0.0508135929607
272 : b, m = 1.47994244714 1.96541248634 , MSE = 0.050806203238
276 : b, m = 1.48054161728 1.96385049656 , MSE = 0.0507994130159
280 : b, m = 1.4811159692 1.96235320595 , MSE = 0.0507931736592
284 : b, m = 1.4816665309 1.96091793458 , MSE = 0.0507874404782
288 : b, m = 1.4821942878 1.95954211357 , MSE = 0.0507821724088
292 : b, m = 1.48270018448 1.95822328041 , MSE = 0.0507773317183
296 : b, m = 1.48318512642 1.95695907462 , MSE = 0.0507728837349
300 : b, m = 1.4836499816 1.95574723348 , MSE = 0.0507687965998
304 : b, m = 1.48409558201 1.954585588 , MSE = 0.0507650410387
308 : b, m = 1.48452272522 1.95347205901 , MSE = 0.0507615901523
312 : b, m = 1.48493217573 1.95240465348 , MSE = 0.0507584192235
316 : b, m = 1.4853246664 1.95138146095 , MSE = 0.0507555055402
320 : b, m = 1.48570089973 1.95040065006 , MSE = 0.0507528282332
324 : b, m = 1.48606154909 1.94946046531 , MSE = 0.0507503681262
328 : b, m = 1.48640726001 1.94855922395 , MSE = 0.0507481075984
332 : b, m = 1.48673865124 1.94769531289 , MSE = 0.0507460304589
336 : b, m = 1.48705631592 1.94686718587 , MSE = 0.0507441218299
340 : b, m = 1.48736082261 1.9460733607 , MSE = 0.0507423680409
344 : b, m = 1.48765271634 1.94531241654 , MSE = 0.0507407565302
348 : b, m = 1.48793251954 1.94458299143 , MSE = 0.0507392757554
352 : b, m = 1.48820073302 1.94388377984 , MSE = 0.0507379151103
356 : b, m = 1.48845783683 1.94321353027 , MSE = 0.0507366648493
360 : b, m = 1.48870429115 1.9425710431 , MSE = 0.0507355160173
364 : b, m = 1.48894053709 1.94195516839 , MSE = 0.0507344603858
368 : b, m = 1.48916699749 1.9413648038 , MSE = 0.0507334903937
372 : b, m = 1.48938407768 1.94079889271 , MSE = 0.0507325990934
376 : b, m = 1.48959216619 1.9402564222 , MSE = 0.050731780101
380 : b, m = 1.48979163547 1.93973642136 , MSE = 0.0507310275504
384 : b, m = 1.48998284254 1.93923795946 , MSE = 0.0507303360514
388 : b, m = 1.49016612963 1.93876014435 , MSE = 0.0507297006512
392 : b, m = 1.49034182478 1.93830212081 , MSE = 0.0507291167986
396 : b, m = 1.49051024246 1.93786306905 , MSE = 0.0507285803118
400 : b, m = 1.49067168412 1.93744220325 , MSE = 0.0507280873482
404 : b, m = 1.49082643871 1.93703877012 , MSE = 0.0507276343768
408 : b, m = 1.49097478321 1.9366520476 , MSE = 0.0507272181534
412 : b, m = 1.49111698313 1.9362813435 , MSE = 0.0507268356966
416 : b, m = 1.491253293 1.93592599432 , MSE = 0.0507264842671
420 : b, m = 1.49138395677 1.93558536407 , MSE = 0.0507261613477
424 : b, m = 1.49150920832 1.93525884305 , MSE = 0.0507258646256
428 : b, m = 1.49162927183 1.93494584685 , MSE = 0.0507255919755
432 : b, m = 1.4917443622 1.93464581526 , MSE = 0.0507253414444
436 : b, m = 1.4918546854 1.93435821128 , MSE = 0.050725111238
440 : b, m = 1.49196043891 1.93408252014 , MSE = 0.0507248997074
444 : b, m = 1.49206181201 1.93381824839 , MSE = 0.0507247053375
448 : b, m = 1.49215898613 1.93356492304 , MSE = 0.0507245267361
452 : b, m = 1.4922521352 1.93332209068 , MSE = 0.0507243626239
456 : b, m = 1.49234142595 1.93308931667 , MSE = 0.0507242118256
460 : b, m = 1.49242701819 1.93286618439 , MSE = 0.0507240732609
464 : b, m = 1.49250906511 1.93265229447 , MSE = 0.0507239459375
468 : b, m = 1.49258771357 1.93244726408 , MSE = 0.0507238289434
472 : b, m = 1.49266310433 1.93225072625 , MSE = 0.0507237214405
476 : b, m = 1.49273537233 1.93206232921 , MSE = 0.050723622659
480 : b, m = 1.49280464692 1.93188173576 , MSE = 0.0507235318913
484 : b, m = 1.49287105209 1.93170862267 , MSE = 0.0507234484872
488 : b, m = 1.49293470669 1.9315426801 , MSE = 0.0507233718493
492 : b, m = 1.49299572466 1.93138361102 , MSE = 0.0507233014288
496 : b, m = 1.4930542152 1.93123113075 , MSE = 0.0507232367213
Final result: m = 1.93108496636 , b = 1.49311028301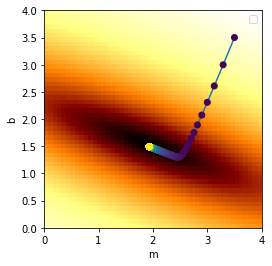
Note that the optimized values \((m,b)\) that we find may not exactly match the “exact” values we used to make the data, because the noise we added to the data can throw this off. In the limit where the noise amplitude goes to zero, our optimized values will exactly match the “exact” values used to generated the data.
Let’s see the results of our line fit…
# plot the points
fig, ax = plt.subplots()
ax.update({'xlabel':'x', 'ylabel':'y'})
ax.plot(x_data,y_data,'o')
ax.set_ylim([0,ax.get_ylim()[1]*1.1])
# and plot the line we fit
xlim = ax.get_xlim()
x_line = np.linspace(xlim[0],xlim[1],2)
y_line = m*x_line + b
ax.plot(x_line,y_line)
plt.show()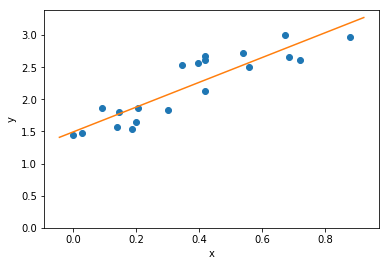
Great!
We can generalize the technique describe above to fit polynomials \[ f(x) = c_0 + c_1 x + c_2 x^2 + ...c_k x^k,\] where \(c_0...c_k\) are the parameters we will tune, and \(k\) is the order of the polynomial. (Typically people use the letter \(a\) for polynomial coefficients, but in the math rendering of Jupter, \(\alpha\) and \(a\) look too much alike, so we’ll use \(c\).) Written more succinctly, \[ f(x) = \sum_{j=0}^k c_j x^j.\]
(Indeed, we could even try non-polynomial basis functions, e.g., $ f(x) = c_0 + c_1 g(x) + c_2 h(x) + …,$ but let’s stick to polynomials for now.)
The key thing to note is that for each parameter \(c_j\), the update \(\Delta c_j\) will be
\[\Delta c_j = -\alpha {\partial (MSE)\over \partial c_j} = -\alpha {\partial (MSE)\over \partial f}{\partial f\over \partial c_j}\] \[= -\alpha {2\over n}\sum_{i=1}^n [f(x_i)-y_i](x_i)^{j} \]
(Note that we are not taking the derivative with respect to \(x_i\), but rather with respect to \(c_j\). Thus there is no “power rule” that needs be applied to this derivative. Also there is no sum over j.)
The following is a complete code for doing this, along with some added refinements:
from __future__ import print_function # for backwards-compatibility w/ Python2
import numpy as np, matplotlib.pyplot as plt
def f(x,c):
y = 0*x # f will work on single floats or arrays
for j in range(c.size):
y += c[j]*(x**j)
return y
def polyfit(x_data,y_data, c_start=None, order=None, maxiter=500, printevery = 25,
alpha_start=0.9, alpha_start_power=0.3):
# function definitions
def MSE(x_arr,y_arr,c):
f_arr = f(x_arr,c)
return ((f_arr - y_arr)**2).mean()
def dMSEdcj(x_arr,y_arr,c,j): # deriviative of MSE wrt cj (*not* wrt x!)
f_arr = f(x_arr,c)
return ( 2* ( f_arr - y_arr) * x_arr**j ).mean()
if ((c_start is None) and (order is None)):
print("Error: Either specify initial guesses for coefficients,",
"or specify the order of the polynomial")
raise # halt
if c_start is not None:
order = c_start.size-1
c = np.copy(c_start)
elif order is not None:
c = np.random.uniform(size=order+1) # random guess for starting point
assert(c.size == order+1) # check against conflicting info
k = order
print(" Initial guess: c = " ,np.array_str(c, precision=2))
alpha = np.ones(c.size)
for j in range(c.size): # start with smaller alphas for higher powers of x
alpha[j] = alpha_start*(alpha_start_power)**(j)
MSE_old = 1e99
for iter in range(maxiter+1): # do the descent
for j in range(c.size):
c[j] = c[j] - alpha[j] * dMSEdcj(x_data,y_data,c,j)
MSE_cur = MSE(x_data,y_data,c)
if (MSE_cur > MSE_old): # adjust if runaway behavior starts
alpha[j] *= 0.3
print(" Notice: decreasing alpha[",j,"] to ",alpha[j])
MSE_old = MSE_cur
if (0 == iter % printevery): # progress log
print('{:4d}'.format(iter),"/",maxiter,": MSE =",'{:9.6g}'.format(MSE_cur),
", c = ",np.array_str(c, precision=3),sep='')
print("")
return c
# Set up input data
n = 100
np.random.seed(2) # for reproducability
x_data = np.random.uniform(-2.5,3,size=n) # some random points for x
c_data = np.array([-4,-3,5,.5,-2,.5]) # params to generate data (5th-degree polynomial)
y_data = f(x_data, c_data)
y_data += 0.02*np.random.normal(size=n)*y_data # add a (tiny) bit of noise
#---- Perform Least Squares Fit
c = polyfit(x_data, y_data, c_start=c_data*np.random.random(), maxiter=500)
#----- Plot the results
def plot_data_and_curve(x_data,y_data,axis_labels=('x','y'), ):
# plot the points
fig, ax = plt.subplots()
ax.update({'xlabel':axis_labels[0], 'ylabel':axis_labels[1]})
ax.plot(x_data,y_data,'o')
# and plot the curve we fit
xlim = ax.get_xlim()
x_line = np.linspace(xlim[0],xlim[1],100)
y_line = f(x_line, c)
ax.plot(x_line,y_line)
plt.show()
plot_data_and_curve(x_data,y_data) Initial guess: c = [-3.52 -2.64 4.4 0.44 -1.76 0.44]
Notice: decreasing alpha[ 3 ] to 0.00729
Notice: decreasing alpha[ 4 ] to 0.002187
Notice: decreasing alpha[ 5 ] to 0.0006561
0/500: MSE = 258.233, c = [-5.438 -1.633 4.24 0.555 -1.904 0.765]
Notice: decreasing alpha[ 5 ] to 0.00019683
25/500: MSE = 0.529541, c = [-4.265 -1.545 5.668 -0.392 -2.146 0.612]
50/500: MSE = 0.424417, c = [-4.304 -1.808 5.659 -0.241 -2.137 0.595]
75/500: MSE = 0.335586, c = [-4.256 -2.034 5.552 -0.105 -2.115 0.578]
100/500: MSE = 0.275848, c = [-4.212 -2.218 5.457 0.006 -2.096 0.564]
125/500: MSE = 0.236521, c = [-4.175 -2.367 5.38 0.096 -2.08 0.553]
150/500: MSE = 0.21068, c = [-4.146 -2.488 5.317 0.17 -2.068 0.544]
175/500: MSE = 0.193702, c = [-4.122 -2.586 5.267 0.229 -2.058 0.537]
200/500: MSE = 0.182549, c = [-4.103 -2.665 5.226 0.277 -2.049 0.531]
225/500: MSE = 0.175222, c = [-4.087 -2.73 5.192 0.316 -2.042 0.526]
250/500: MSE = 0.170408, c = [-4.075 -2.782 5.165 0.347 -2.037 0.522]
275/500: MSE = 0.167245, c = [-4.064 -2.824 5.143 0.373 -2.033 0.519]
300/500: MSE = 0.165167, c = [-4.056 -2.859 5.126 0.393 -2.029 0.516]
325/500: MSE = 0.163802, c = [-4.049 -2.886 5.111 0.41 -2.026 0.514]
350/500: MSE = 0.162905, c = [-4.044 -2.909 5.1 0.424 -2.024 0.513]
375/500: MSE = 0.162316, c = [-4.039 -2.927 5.09 0.435 -2.022 0.511]
400/500: MSE = 0.161929, c = [-4.036 -2.942 5.083 0.444 -2.02 0.51 ]
425/500: MSE = 0.161675, c = [-4.033 -2.954 5.076 0.451 -2.019 0.509]
450/500: MSE = 0.161508, c = [-4.031 -2.964 5.071 0.457 -2.018 0.508]
475/500: MSE = 0.161398, c = [-4.029 -2.972 5.067 0.462 -2.017 0.508]
500/500: MSE = 0.161326, c = [-4.027 -2.978 5.064 0.465 -2.017 0.507]
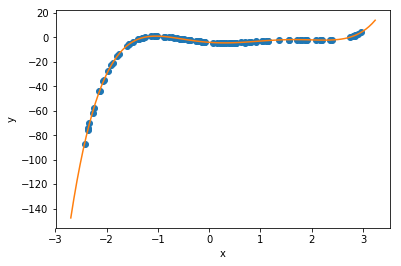
Now, it turns out that polynomials are often terrible things to try to fit arbitrary data with, because they can ‘blow up’ as \(|x|\) increases, and this causes instability. But for a variety of physics problems (see below), polynomials can be just what we’re after. Plus, that made a nice demonstration, for now.
(For more general functions, I actually wrote a multi-parameter SymPy gradient-descient that is completely general, but it’s terrifically slow so I won’t be posting it here. If you really want it, contact me.)
Ok. Now we’re all we’re going to do next is fit a parabola to the motion of a falling ball – and that’s supposed to tell us something deep about physics. Sounds silly, right? ‘Everybody’ knows objects moving in a gravitational field follow parabolas (both in space & time); the more math-savvy may complain that we’re simply going to ‘get out of this’ what we ‘put into it.’
Well, from a philosophical standpoint and from the way that these methods will generalize to other situations, there are significant implications from the methodology we’re about to follow.
The Challenge: Given a set of one-dimensional data of position vs. time \(y(t)\), can we find the underlying equation that gives rise to it? Better put, can we fit a model to it, and how well can we fit it, and what kind of model will it be anyway?
(This is the sort of thing that statisticians do, but it’s also something physicists do, and one could argue, this is what everybody does all the time. )
Let’s get started. I’m just going to specify y(t) at a series of \(n+1\) time steps \(t_i\) (\(t_0\)…\(t_n\)) and we’ll make them evenly spaced, and we’ll leave out any noise at all – perfect data. :-)
g_exact = 9.8 # a physical parater we'll find a fit for
dt = 0.01
tmax = 1 # number of time steps
t_data = np.arange(0,tmax,step=dt) # time values
nt = t_data.size
print("dt = ",dt,", nt = ",nt)
y0 = 1.234 # initial position, choose anything
v0 = 3.1415 # initial velocity
#assign the data
y_data = y0 + v0*t_data - 0.5 * g_exact * t_data**2
# y_data *= np.random.uniform(low=.9, high=1.1, size=(y_data.size)) # for later; add noise in
plot_data(t_data,y_data, axis_labels=('t','y'))dt = 0.01 , nt = 100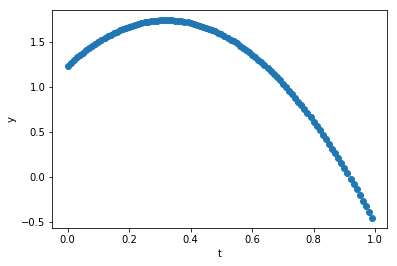
Can we fit this with a polynomial? Sure, let’s do that, using the code from before…
c = polyfit(t_data, y_data, order=2, alpha_start = 10.0, maxiter=1000, printevery=100)
print("Our fit: y(t) = ",c[0]," + ",c[1],"*t + ",c[2],"*t**2",sep='')
print("Compare to exact: y(t) = ",y0, " + ",v0, "*t - ",0.5*g_exact,"*t**2",sep='')
print("Estimate for g = ",-2*c[2])
plot_data_and_curve(t_data,y_data, axis_labels=('t','y')) Initial guess: c = [ 0.72 0.71 0.77]
0/1000: MSE = 5.41899, c = [-2.186 7.319 -1.042]
Notice: decreasing alpha[ 0 ] to 3.0
Notice: decreasing alpha[ 0 ] to 0.9
100/1000: MSE =0.0314071, c = [ 1.642 0.749 -2.528]
200/1000: MSE =0.00280409, c = [ 1.356 2.427 -4.191]
300/1000: MSE =0.000250355, c = [ 1.27 2.928 -4.688]
400/1000: MSE =2.23522e-05, c = [ 1.245 3.078 -4.837]
500/1000: MSE =1.99565e-06, c = [ 1.237 3.122 -4.881]
600/1000: MSE =1.78176e-07, c = [ 1.235 3.136 -4.894]
700/1000: MSE =1.59079e-08, c = [ 1.234 3.14 -4.898]
800/1000: MSE =1.42029e-09, c = [ 1.234 3.141 -4.899]
900/1000: MSE =1.26806e-10, c = [ 1.234 3.141 -4.9 ]
1000/1000: MSE =1.13215e-11, c = [ 1.234 3.141 -4.9 ]
Our fit: y(t) = 1.23400775143 + 3.14145457517*t + -4.89995497009*t**2
Compare to exact: y(t) = 1.234 + 3.1415*t - 4.9*t**2
Estimate for g = 9.79990994018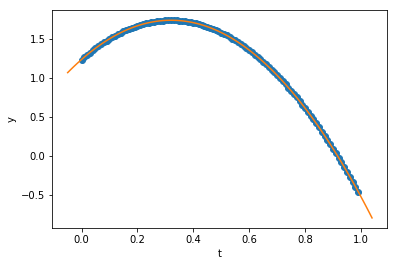
What if we try fitting higher-order terms? Are their coefficients negligible? The system may converge, but it will take a lot more iterations… (be prepared to wait!)
c = polyfit(t_data, y_data, order=3, alpha_start = 1.0, maxiter=700000, printevery=10000)
print("Our fit: y(t) = ",c[0]," + ",c[1],"*t + ",c[2],"*t**2 + ",c[3],"*t**3",sep='')
print("Compare to exact: y(t) = ",y0, " + ",v0, "*t - ",0.5*g_exact,"*t**2",sep='')
print("Estimate for g = ",-2*c[2]) Initial guess: c = [ 0.33 0.23 0.63 0.41]
0/700000: MSE = 0.828106, c = [ 1.189 -0.045 0.563 0.398]
Notice: decreasing alpha[ 0 ] to 0.3
10000/700000: MSE =0.000464818, c = [ 1.291 2.454 -3.188 -1.138]
20000/700000: MSE =0.000369748, c = [ 1.285 2.528 -3.373 -1.015]
30000/700000: MSE =0.000294122, c = [ 1.279 2.594 -3.538 -0.906]
40000/700000: MSE =0.000233965, c = [ 1.275 2.654 -3.685 -0.808]
50000/700000: MSE =0.000186111, c = [ 1.27 2.706 -3.817 -0.72 ]
60000/700000: MSE =0.000148045, c = [ 1.266 2.753 -3.934 -0.642]
70000/700000: MSE =0.000117765, c = [ 1.263 2.795 -4.038 -0.573]
80000/700000: MSE =9.36783e-05, c = [ 1.26 2.833 -4.131 -0.511]
90000/700000: MSE =7.4518e-05, c = [ 1.257 2.866 -4.214 -0.456]
100000/700000: MSE =5.92766e-05, c = [ 1.254 2.896 -4.289 -0.407]
110000/700000: MSE =4.71526e-05, c = [ 1.252 2.922 -4.355 -0.363]
120000/700000: MSE =3.75083e-05, c = [ 1.25 2.946 -4.414 -0.323]
130000/700000: MSE =2.98366e-05, c = [ 1.248 2.967 -4.466 -0.288]
140000/700000: MSE =2.37341e-05, c = [ 1.247 2.986 -4.513 -0.257]
150000/700000: MSE =1.88797e-05, c = [ 1.246 3.003 -4.555 -0.229]
160000/700000: MSE =1.50182e-05, c = [ 1.244 3.018 -4.592 -0.205]
170000/700000: MSE =1.19465e-05, c = [ 1.243 3.031 -4.626 -0.183]
180000/700000: MSE =9.50301e-06, c = [ 1.242 3.043 -4.655 -0.163]
190000/700000: MSE =7.55933e-06, c = [ 1.241 3.054 -4.682 -0.145]
200000/700000: MSE =6.0132e-06, c = [ 1.24 3.063 -4.705 -0.129]
210000/700000: MSE =4.7833e-06, c = [ 1.24 3.072 -4.726 -0.115]
220000/700000: MSE =3.80496e-06, c = [ 1.239 3.079 -4.745 -0.103]
230000/700000: MSE =3.02672e-06, c = [ 1.239 3.086 -4.762 -0.092]
240000/700000: MSE =2.40766e-06, c = [ 1.238 3.092 -4.777 -0.082]
250000/700000: MSE =1.91521e-06, c = [ 1.238 3.097 -4.79 -0.073]
260000/700000: MSE =1.52349e-06, c = [ 1.237 3.102 -4.802 -0.065]
270000/700000: MSE =1.21188e-06, c = [ 1.237 3.106 -4.813 -0.058]
280000/700000: MSE =9.64014e-07, c = [ 1.237 3.11 -4.822 -0.052]
290000/700000: MSE =7.66841e-07, c = [ 1.236 3.114 -4.83 -0.046]
300000/700000: MSE =6.09997e-07, c = [ 1.236 3.117 -4.838 -0.041]
310000/700000: MSE =4.85233e-07, c = [ 1.236 3.119 -4.845 -0.037]
320000/700000: MSE =3.85987e-07, c = [ 1.236 3.122 -4.851 -0.033]
330000/700000: MSE =3.0704e-07, c = [ 1.235 3.124 -4.856 -0.029]
340000/700000: MSE =2.4424e-07, c = [ 1.235 3.126 -4.861 -0.026]
350000/700000: MSE =1.94285e-07, c = [ 1.235 3.127 -4.865 -0.023]
360000/700000: MSE =1.54547e-07, c = [ 1.235 3.129 -4.869 -0.021]
370000/700000: MSE =1.22937e-07, c = [ 1.235 3.13 -4.872 -0.019]
380000/700000: MSE =9.77925e-08, c = [ 1.235 3.132 -4.875 -0.017]
390000/700000: MSE =7.77907e-08, c = [ 1.235 3.133 -4.878 -0.015]
400000/700000: MSE =6.188e-08, c = [ 1.235 3.134 -4.88 -0.013]
410000/700000: MSE =4.92235e-08, c = [ 1.235 3.134 -4.882 -0.012]
420000/700000: MSE =3.91556e-08, c = [ 1.235 3.135 -4.884 -0.01 ]
430000/700000: MSE =3.1147e-08, c = [ 1.234 3.136 -4.886 -0.009]
440000/700000: MSE =2.47764e-08, c = [ 1.234 3.136 -4.887 -0.008]
450000/700000: MSE =1.97088e-08, c = [ 1.234 3.137 -4.889 -0.007]
460000/700000: MSE =1.56777e-08, c = [ 1.234 3.138 -4.89 -0.007]
470000/700000: MSE =1.24711e-08, c = [ 1.234 3.138 -4.891 -0.006]
480000/700000: MSE =9.92037e-09, c = [ 1.234 3.138 -4.892 -0.005]
490000/700000: MSE =7.89133e-09, c = [ 1.234e+00 3.139e+00 -4.893e+00 -4.691e-03]
500000/700000: MSE =6.27729e-09, c = [ 1.234e+00 3.139e+00 -4.894e+00 -4.184e-03]
510000/700000: MSE =4.99338e-09, c = [ 1.234e+00 3.139e+00 -4.894e+00 -3.731e-03]
520000/700000: MSE =3.97207e-09, c = [ 1.234e+00 3.139e+00 -4.895e+00 -3.328e-03]
530000/700000: MSE =3.15965e-09, c = [ 1.234e+00 3.140e+00 -4.896e+00 -2.968e-03]
540000/700000: MSE =2.5134e-09, c = [ 1.234e+00 3.140e+00 -4.896e+00 -2.647e-03]
550000/700000: MSE =1.99932e-09, c = [ 1.234e+00 3.140e+00 -4.896e+00 -2.361e-03]
560000/700000: MSE =1.5904e-09, c = [ 1.234e+00 3.140e+00 -4.897e+00 -2.106e-03]
570000/700000: MSE =1.26511e-09, c = [ 1.234e+00 3.140e+00 -4.897e+00 -1.878e-03]
580000/700000: MSE =1.00635e-09, c = [ 1.234e+00 3.140e+00 -4.897e+00 -1.675e-03]
590000/700000: MSE =8.0052e-10, c = [ 1.234e+00 3.141e+00 -4.898e+00 -1.494e-03]
600000/700000: MSE =6.36787e-10, c = [ 1.234e+00 3.141e+00 -4.898e+00 -1.332e-03]
610000/700000: MSE =5.06543e-10, c = [ 1.234e+00 3.141e+00 -4.898e+00 -1.188e-03]
620000/700000: MSE =4.02939e-10, c = [ 1.234e+00 3.141e+00 -4.898e+00 -1.060e-03]
630000/700000: MSE =3.20524e-10, c = [ 1.234e+00 3.141e+00 -4.899e+00 -9.454e-04]
640000/700000: MSE =2.54967e-10, c = [ 1.234e+00 3.141e+00 -4.899e+00 -8.432e-04]
650000/700000: MSE =2.02818e-10, c = [ 1.234e+00 3.141e+00 -4.899e+00 -7.520e-04]
660000/700000: MSE =1.61335e-10, c = [ 1.234e+00 3.141e+00 -4.899e+00 -6.707e-04]
670000/700000: MSE =1.28336e-10, c = [ 1.234e+00 3.141e+00 -4.899e+00 -5.982e-04]
680000/700000: MSE =1.02087e-10, c = [ 1.234e+00 3.141e+00 -4.899e+00 -5.335e-04]
690000/700000: MSE =8.12072e-11, c = [ 1.234e+00 3.141e+00 -4.899e+00 -4.758e-04]
700000/700000: MSE =6.45976e-11, c = [ 1.234e+00 3.141e+00 -4.899e+00 -4.244e-04]
Our fit: y(t) = 1.23402130221 + 3.1412436463*t + -4.89936171114*t**2 + -0.000424401050714*t**3
Compare to exact: y(t) = 1.234 + 3.1415*t - 4.9*t**2
Estimate for g = 9.79872342227So, in this case, we were able to show not only that the data fits a parabola well, but that the higher order term (for \(t^3\)) is negigible!! Great science! In practice, however, for non-perfect data, this does not work out. The higher-order term introduces an extreme sensitivity to the noise, which can render the results inconclusive.
Exercise: Go back to where the data is generated, and uncomment the line that says “# for later; add noise in” and re-run the fitting. You will find that the coefficients for the cubic polynomial do not resemble the original values found at all, whereas the coefficients for a quadratic polynomial, while not being the same as before, will still be “close.”
Thus, by hypothesizing a parabolic dependence, we’re able to correctly deduce the parameters of the motion (initial position & velocity, and acceleration), and we get a very low error in doing so. :-) Trying to show that higher-order terms in a polynomial expansion don’t contribute…that worked for “perfect data” but in a practical case it didn’t work out because polynomials are “ill behaved.” Still, we got some useful physics out of it. And that works for many applications. We could stop here.
…although…
What if our data wasn’t parabolic? Sure, for motion in a uniform gravitational field this is fine, but what if we want to model the sinusoidal motion of a simple harmonic oscillator? In that case, guessing a parabola would only work for very early times (thanks to Taylor’s theorem). Sure, we could fit a model where we’ve explictly put in a sine function in the code – and I encourage you to write your own code to do this – but perhaps there’s a way to deduce the motion, by looking at the local behavior and thereby ‘learning’ the differential equation underlying the motion.
Exercise: Copy the polyfit() code elsewhere (e.g. to text file or a new cell in this Jupyter notebook or a new notebook) and rename it sinefit(), and modify it to fit a sine function instead of a polynomial:
\[y(t) = A\sin(\omega t + \phi),\]
where the fit parameters will be the amplitude \(A\), frequency \(\omega\) and phase constant \(\phi\). Try fitting to data generated for \(A=3\), \(\omega=2\), \(\phi=1.57\) on \(0\le t \le 10\). As an example, you can check your answer against this.-SH
There are lots of schemes that incorporate more sophisticated approaches in order to achieve convergence more reliabily and more quickly than the “simple” gradient descent we’ve been doing.
Such schemes introduce concepts such as “momentum” and go by names such as Adagrad, Adadelta, Adam, RMSProp, etc… For an excellent overview of such methods, I recommend Sebastian Ruder’s blog post which includes some great animations!
{kind=link}