Notes on Convexity of Loss Functions for Classification
(Logistic Regression)
Click here for the Jupyter Notebook version of this post.
Andrew Ng, in Week 3 of his Coursera course on Machine Learning, shows the following image with respect to the “cost function” to be optimized (this is slide 14 of Lecture 6):
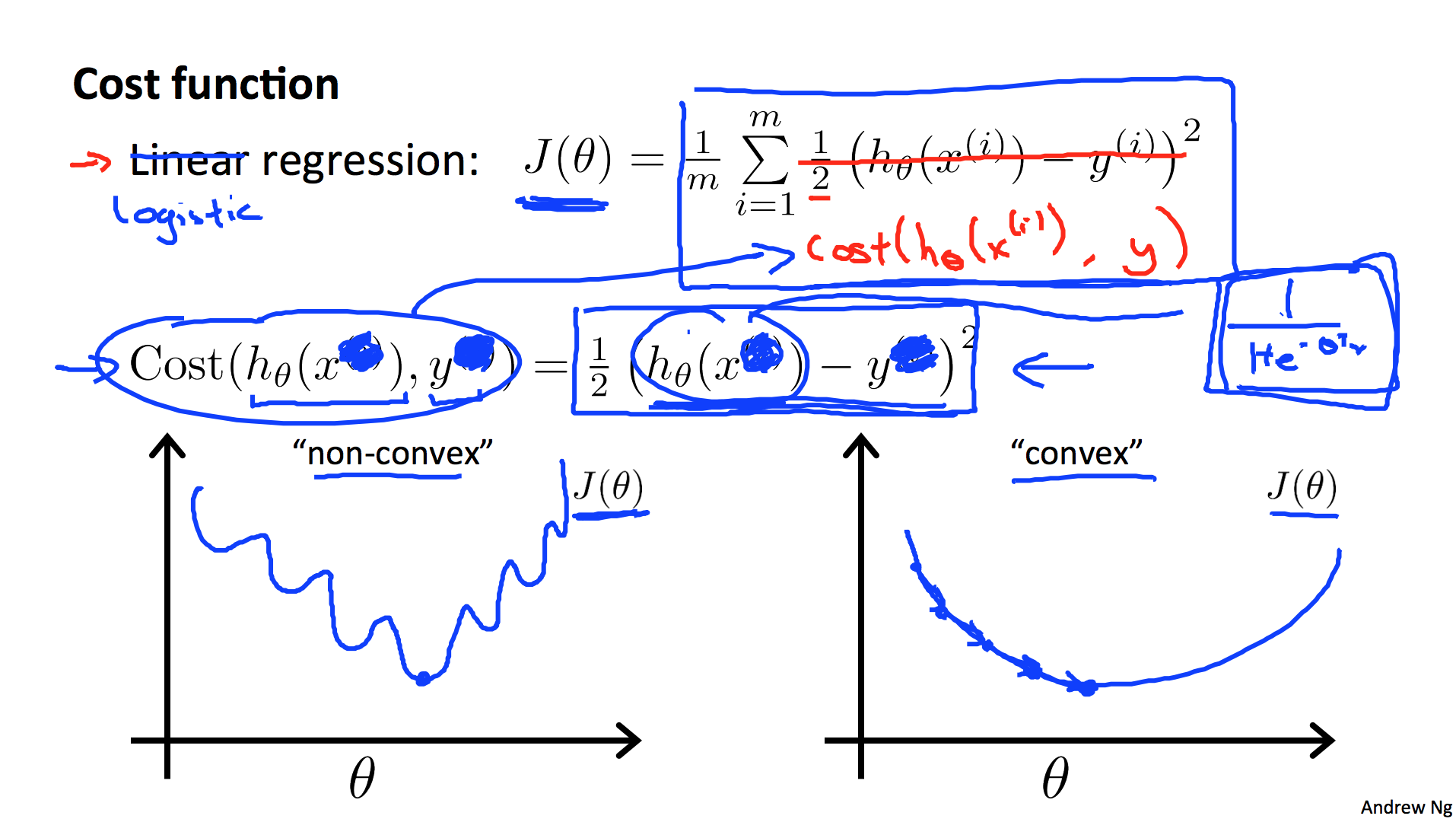
I wanted to investigate this: Could I reproduce the two graphs he sketched? The two different loss functions are the mean squared error (MSE or sometimes just SE) and cross entropy (CE):
\[MSE = {1\over m}\sum_{i=1}^m \left( y_i - h_i \right)^2\] \[CE = - {1\over m}\sum_{i=1}^m \left[ y_i \log(h_i) + (1-y_i) \log(1-h_i) \right]\]where \(y_i\) are the true values (0 or 1) and \(h_i = h(x_i)\) are the predictions.
(Note that CE is part of the Kullback-Liebler (KL) divergence; for supervised learning scenarios, they differ only by a constant. Thus optimizing one is functionally equivalent to optimizing the other, and the following remarks appy to both CE and KL loss. In fact, many people will say ‘KL’ even though they’re really only computing the CE part. For more on this topic, try reading this.)
TL/DR: No I can’t reproduce his sketches. The graph I get for sum of the squared error (SE) doesn’t have the wiggles that his drawing on the left does. (Perhaps he was just doodling an example of an arbitrary non-convex function, rather than the squared loss in particular?) Takeways at the bottom of this, re. the difference between a convex loss function (by itself) vs. a convex loss for a problem – i.e. the individual terms are convex for either function, but the sum of these terms is actually not strictly convex for either function (for this problem).
I read a few posts about this first…
- Math StackExchange: Show that logistic regression with squared loss function is non-convex, which includes a link to this nice demo on Desmos
- https://math.stackexchange.com/questions/2193478/loss-function-for-logistic-regression
- https://en.wikipedia.org/wiki/Loss_functions_for_classification seems to say that squared loss is convex. ??
…but then wanted to try for myself. As follows:
# preliminary set up. ipympl allows for interactive plots; replace it with inline if not working
#%matplotlib ipympl
%matplotlib inline
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
from matplotlib import cm
import numpy as np
# basic functions for data operations
def h(x,a,b): # h = logistic function. a is 'weight' and b is 'bias'
return 1/(1 + np.exp(-(a*x + b))) # For code below, a & b should be scalars, x can be anything
def classify_x(x, threshold):
out = 0*x
out[x > threshold] = 1.0
return out
# define some data
num_x = 25
x_arr = np.linspace(-5,5,num_x) # _arr denotes"array"
threshold = 0.7314 # threshold value chosen arbitrarily
y_arr = classify_x(x_arr, threshold)
# make a prediction
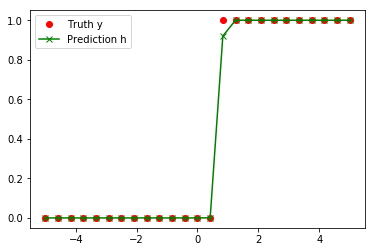
a_guess = 10/(x_arr[1]-x_arr[0])
b_guess = -a_guess * threshold
print("Prediction guess: a =",a_guess,", b =",b_guess)
h_arr = np.array(h(x_arr, a_guess, b_guess))
# plot the data
fig = plt.figure()
plt.plot(x_arr, y_arr,'o',color='red',label="Truth y")
plt.plot(x_arr, h_arr,'x-',color='green',label="Prediction h")
plt.legend()
plt.show()
Prediction guess: a = 24.0 , b = -17.5536
# define a couple loss functions
def calc_se_loss(y_arr, h_arr): # squared error loss
return np.mean( (y_arr - h_arr)**2)
def calc_ce_loss(y_arr, h_arr): # cross-entropy loss, related to Kullback-Liebler divergence
eps = 1.0e-16 # added to avoid log(0) errors
return -np.mean( y_arr*np.log(h_arr) + (1-y_arr)*np.log(1-h_arr+eps) ) # elementwise multiplication
# 1D plot
# define parameter space over which to plot
num_a = 100
a_arr = np.linspace(-a_guess,4*a_guess,num_a)
b_arr = b_guess + 0*a_arr # make at the b's all the same value for this first plot.
se_loss = []
ce_loss = []
for i in range(a_arr.shape[0]): # cycle through all the values of a and b, getting a different loss for each
h_arr = h(x_arr, a_arr[i], b_arr[i])
se_loss.append( calc_se_loss(y_arr, h_arr) )
ce_loss.append( calc_ce_loss(y_arr, h_arr) )
# plot 1-d version
fig = plt.figure()
ax = fig.gca()
ax.set_xlabel('a')
#ax.set_ylim(2.38, 2.41) # zoom in on flat part on the right
plt.plot(a_arr, np.log(se_loss),'o-',color='red',label="SE Loss")
plt.plot(a_arr, np.log(ce_loss),'o-',color='blue',label="CE Loss")
ax.set_ylabel("log of loss")
plt.legend()
plt.show()
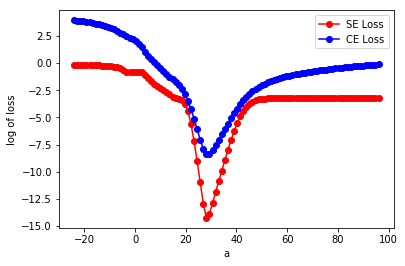
In the above figure, it looks like the SE loss goes ‘flat’ for a bit on the left, but never turns upward until after the global minimum. The CE loss…I can see a few places where we could connect two points with a straight line and not have all of the line lie with in the epigraph. Still the lack of flat regions for the blue line would make it preferable for gradient-based optimization.
Plot the full error surface
num_a = 100
# try experimenting: play around with the max & min of the a & b values to see the surface
a_arr = np.linspace(-a_guess/2,a_guess*2,num_a)
b_arr = np.linspace(b_guess*2,-b_guess/2,num_a)
A, B = np.meshgrid(a_arr, b_arr)
def plot_loss_surf(A, B, x_arr, loss='SE'):
Z = np.zeros([len(A), len(B)])
if ('SE' == loss):
for i in range(len(A)):
for j in range(len(B)):
h_arr = h(x_arr, a_arr[i], b_arr[j])
Z[j, i] = calc_se_loss(y_arr, h_arr)
else:
for i in range(len(A)):
for j in range(len(B)):
h_arr = h(x_arr, a_arr[i], b_arr[j])
Z[j, i] = calc_ce_loss(y_arr, h_arr)
fig = plt.figure()
ax = fig.gca(projection='3d')
surf = ax.plot_surface(A, B, np.log(Z), cmap=cm.coolwarm,
linewidth=0, antialiased=False)
ax.set_xlabel('a')
ax.set_ylabel('b')
ax.set_zlabel('log('+loss+')')
#ax.set_zlim(2, 2.5)
ax.set_title(loss+' loss')
#fig.colorbar(surf, shrink=0.5, aspect=5) # Add a color bar which maps values to colors.
plt.show()
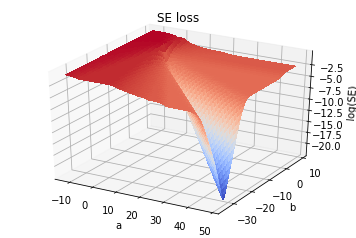
plot_loss_surf(A,B,x_arr,loss='SE')
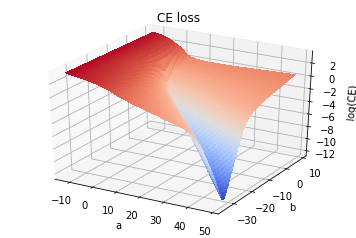
plot_loss_surf(A,B,x_arr,loss='CE')
The Verdict
So, although the individual terms \((y_i - h_i)^2\) and/or \([y_i\log(h_i)+(1-y_i)\log(1-h_i)]\) are individually convex, the sum for either type of loss terms is actually non-convex for this problem. Although neither give rise to unwanted local minima for this problem.
The SE loss, while at least not having any non-global minima, still has multiple significant flat regions that would prove tedious for gradient descent optimiazation, whereas in contrast, the CE loss is smoother and is strictly monotonic on either side of the global minimum. The the CE loss (and/or KL divergence) would be preferable for this problem – you could do it with SE loss assuming you had momentum or some fancy optimization algorithm, but it would take longer and why bother?
A better way to describe this may be in terms of the ‘flat regions’. As we see in this nice demo on Desmos, what the -log function does is take the “flattening” and blow it up into a significant slope: the smaller the value, the larger the -log. This has a way of making things ‘curved’ when the SE values seem to be flattening out. In this sense, the CE loss would seem to preferable for many cases, so long as the predictions \(h_i\) stay bounded between 0 and 1. This is why it is not recommended for regression problems which may not be bounded in such a way. If, however, you can keep your regression values between 0 and 1, this may be worthwhile. The trade-off is that by bounding the output layer of a regression solver in such a away, you may introduce a new form of “vanishing gradients” – i.e. you move these from the loss function into, say, the activation of your last network layer.
Aside: Solve the logistic regression problem using scikit-learn
from sklearn import linear_model
clf = linear_model.LogisticRegression(C=1e5)
clf.fit(x_arr[:, np.newaxis], y_arr)
a_fit, b_fit = clf.coef_[0][0], clf.intercept_[0]
print("Fit paramters: a =",a_fit,", b =",b_fit)
print("Predicted threshold: x = ",-b_fit/a_fit)
Fit paramters: a = 26.5300439723 , b = -16.5422018244
Predicted threshold: x = 0.623527116718
Afterward: “But you still haven’t found the global minimum!”
In the surface plots above, we see the minimum of the surface going lower and lower – even lower than the supposedly ‘optimum’ parameters we just found via scikit-learn. The reason is that there is no optimal paramter combination: The steepness parameter \(a\) of the sigmoid function \(h(x)\) is only bounded from below by the data in this problem. Thus there is no upper bound. The data will constrain the center of the sigmoid \(x_0 = -b/a\) to some extent (i.e. it needs to lie between two values of \(x_i\)), but other than that…
So how then does the loss function seem to get lower and lower? The steeper the sigmoid function, the more closely its values will approach 0 and 1 on either side. Thus for this problem, the optimal solution is \(a \rightarrow \infty\), with \(b = -({\rm threshold})/a\).
Comments?
I’d love feedback, especially from those more experienced in these matters. Any thoughts?